July Events - BlackBerry Mini Jam and Devel Conference
If you happen to be on holiday in Bulgaria but would still like to meet some hackers there are three events this month that I find interesting: Plovdiv Conf, BlackBerry Mini Developer Jam and Varna Conf.
 Image: source code from a game development course held at Sofia University couple of years ago.
Own work.
Image: source code from a game development course held at Sofia University couple of years ago.
Own work.
Plovdiv Conf
Plovdiv Conf will be held at the Plovdiv Fair on July 6th 2013. There isn't an official program but the speaker profiles are interesting. Among them are guys well known for their Ruby and Linux skills.
From the given list I recognize only half the names. One speaker that sounds interesting to me claims experience with programming assembler for the mainframe.
My friend Alexander Kurtakov from Red Hat/Eclipse will be there as well so I'm planning to attend this event.
BlackBerry 10 Mini Jam Sofia
Organized by BlackBerry Developer Group Balkan the BlackBerry 10 Mini Jam Sofia will be held on July 11th 2013 at betahaus Sofia. Last time I visited a BlackBerry developers session it was very interesting.
My personal interest at the moment is not developing mobile applications but I'd like to hear more about the possibilities. My understanding is that BlackBerry 10 is much more flexible as a development platform compared to Android and iOS.
I will definitely attend this event because there will be a shiny new BlackBerry Z 10 waiting for me there :). I will tell you how to secure one after I get it.
Varna Conf
Varna Conf is organized by the same people who do Plovdiv Conf. It will be held on July 20th 2013 at Cherno More hotel in Varna.
Most of the speakers I don't know but there are couple of topics about testing and refactoring which look interesting. However I will be more likely to socialize with the local development groups rather than listening to all talks.
I'm not sure if I will attend though. My initial plan was to attend but there are other personal errands that are popping up. Given that it is not near Sofia I will probably skip it.
If you happen to be on holiday at the Bulgarian sea side however, you should definitely check it out. And Varna is a very nice city too.
Let me know if there are other interesting events in the vicinity! Use the comments and tell me where are you going this month.
There are comments.
Performance test: Amazon ElastiCache vs Amazon S3
Which Django cache backend is faster? Amazon ElastiCache or Amazon S3 ?
Previously I've mentioned about using Django's cache to keep state between HTTP requests. In my demo described there I was using django-s3-cache. It is time to move to production so I decided to measure the performance difference between the two cache options available at Amazon Web Services.
Update 2013-07-01: my initial test may have been false since I had not configured ElastiCache access properly. I saw no errors but discovered the issue today on another system which was failing to store the cache keys but didn't show any errors either. I've re-run the tests and updated times are shown below.
Test infrastructure
- One Amazon S3 bucket, located in US Standard (aka US East) region;
- One Amazon ElastiCache cluster with one Small Cache Node (cache.m1.small) with Moderate I/O capacity;
- One Amazon Elasticache cluster with one Large Cache Node (cache.m1.large) with High I/O Capacity;
- Update: I've tested both
python-memcachedandpylibmcclient libraries for Django; - Update: Test is executed from an EC2 node in the us-east-1a availability zone;
- Update: Cache clusters are in the us-east-1a availability zone.
Test Scenario
The test platform is Django. I've created a
skeleton project
with only CACHES settings
defined and necessary dependencies installed. A file called test.py holds the
test cases, which use the standard timeit module. The object which is stored in cache
is very small - it holds a phone/address identifiers and couple of user made selections.
The code looks like this:
import timeit
s3_set = timeit.Timer(
"""
for i in range(1000):
my_cache.set(i, MyObject)
"""
,
"""
from django.core import cache
my_cache = cache.get_cache('default')
MyObject = {
'from' : '359123456789',
'address' : '6afce9f7-acff-49c5-9fbe-14e238f73190',
'hour' : '12:30',
'weight' : 5,
'type' : 1,
}
"""
)
s3_get = timeit.Timer(
"""
for i in range(1000):
MyObject = my_cache.get(i)
"""
,
"""
from django.core import cache
my_cache = cache.get_cache('default')
"""
)
Tests were executed from the Django shell on my laptop
on an EC2 instance in the us-east-1a availability zone. ElastiCache nodes
were freshly created/rebooted before test execution. S3 bucket had no objects.
$ ./manage.py shell
Python 2.6.8 (unknown, Mar 14 2013, 09:31:22)
[GCC 4.6.2 20111027 (Red Hat 4.6.2-2)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
>>> from test import *
>>>
>>>
>>>
>>> s3_set.repeat(repeat=3, number=1)
[68.089607000350952, 70.806712865829468, 72.49261999130249]
>>>
>>>
>>> s3_get.repeat(repeat=3, number=1)
[43.778793096542358, 43.054368019104004, 36.19232702255249]
>>>
>>>
>>> pymc_set.repeat(repeat=3, number=1)
[0.40637087821960449, 0.3568730354309082, 0.35815882682800293]
>>>
>>>
>>> pymc_get.repeat(repeat=3, number=1)
[0.35759496688842773, 0.35180497169494629, 0.39198613166809082]
>>>
>>>
>>> libmc_set.repeat(repeat=3, number=1)
[0.3902890682220459, 0.30157709121704102, 0.30596804618835449]
>>>
>>>
>>> libmc_get.repeat(repeat=3, number=1)
[0.28874802589416504, 0.30520200729370117, 0.29050207138061523]
>>>
>>>
>>> libmc_large_set.repeat(repeat=3, number=1)
[1.0291709899902344, 0.31709098815917969, 0.32010698318481445]
>>>
>>>
>>> libmc_large_get.repeat(repeat=3, number=1)
[0.2957158088684082, 0.29067802429199219, 0.29692888259887695]
>>>
Results
As expected ElastiCache is much faster (10x) compared to S3. However the difference between the two ElastiCache node types is subtle. I will stay with the smallest possible node to minimize costs. Also as seen, pylibmc is a bit faster compared to the pure Python implementation.
Depending on your objects size or how many set/get operations you perform per second you may need to go with the larger nodes. Just test it!
It surprised me how slow django-s3-cache is.
The false test showed django-s3-cache to be 100x slower but new results are better.
10x decrease in performance sounds about right for a filesystem backed cache.
A quick look at the code of the two backends shows some differences. The one I immediately see is that for every cache key django-s3-cache creates an sha1 hash which is used as the storage file name. This was modeled after the filesystem backend but I think the design is wrong - the memcached backends don't do this.
Another one is that django-s3-cache time-stamps all objects and uses pickle to serialize them. I wonder if it can't just write them as binary blobs directly. There's definitely lots of room for improvement of django-s3-cache. I will let you know my findings once I get to it.
There are comments.
Twilio is Located in Amazon Web Services US East
Where do I store my audio files in order to minimize download and call wait time?
Twilio is a cloud vendor that provides telephony services.
It can download and <Play> arbitrary audio files and will cache the files
for better performance.
Twilio support told me they are not disclosing the location of their servers, so from my web application hosted in AWS US East:
[ivr-otb.rhcloud.com logs]\> grep TwilioProxy access_log-* | cut -f 1 -d '-' | sort | uniq
10.125.90.172
10.214.183.239
10.215.187.220
10.245.155.18
10.255.119.159
10.31.197.102
Now let's map these addresses to host names. From another EC2 system, also in Amazon US East:
[ec2-user@ip-10-29-206-86 ~]$ dig -x 10.125.90.172 -x 10.214.183.239 -x 10.215.187.220 -x 10.245.155.18 -x 10.255.119.159 -x 10.31.197.102
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.17.rc1.29.amzn1 <<>> -x 10.125.90.172 -x 10.214.183.239 -x 10.215.187.220 -x 10.245.155.18 -x 10.255.119.159 -x 10.31.197.102
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 43245
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;172.90.125.10.in-addr.arpa. IN PTR
;; ANSWER SECTION:
172.90.125.10.in-addr.arpa. 113 IN PTR ip-10-125-90-172.ec2.internal.
;; Query time: 1 msec
;; SERVER: 172.16.0.23#53(172.16.0.23)
;; WHEN: Mon Jun 24 20:48:21 2013
;; MSG SIZE rcvd: 87
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 52693
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;239.183.214.10.in-addr.arpa. IN PTR
;; ANSWER SECTION:
239.183.214.10.in-addr.arpa. 42619 IN PTR domU-12-31-39-0B-B0-01.compute-1.internal.
;; Query time: 0 msec
;; SERVER: 172.16.0.23#53(172.16.0.23)
;; WHEN: Mon Jun 24 20:48:21 2013
;; MSG SIZE rcvd: 100
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 25255
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;220.187.215.10.in-addr.arpa. IN PTR
;; ANSWER SECTION:
220.187.215.10.in-addr.arpa. 43140 IN PTR domU-12-31-39-0C-B8-2E.compute-1.internal.
;; Query time: 0 msec
;; SERVER: 172.16.0.23#53(172.16.0.23)
;; WHEN: Mon Jun 24 20:48:21 2013
;; MSG SIZE rcvd: 100
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 15099
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;18.155.245.10.in-addr.arpa. IN PTR
;; ANSWER SECTION:
18.155.245.10.in-addr.arpa. 840 IN PTR ip-10-245-155-18.ec2.internal.
;; Query time: 0 msec
;; SERVER: 172.16.0.23#53(172.16.0.23)
;; WHEN: Mon Jun 24 20:48:21 2013
;; MSG SIZE rcvd: 87
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 28878
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;159.119.255.10.in-addr.arpa. IN PTR
;; ANSWER SECTION:
159.119.255.10.in-addr.arpa. 43140 IN PTR domU-12-31-39-01-70-51.compute-1.internal.
;; Query time: 0 msec
;; SERVER: 172.16.0.23#53(172.16.0.23)
;; WHEN: Mon Jun 24 20:48:21 2013
;; MSG SIZE rcvd: 100
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 28727
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;102.197.31.10.in-addr.arpa. IN PTR
;; ANSWER SECTION:
102.197.31.10.in-addr.arpa. 840 IN PTR ip-10-31-197-102.ec2.internal.
;; Query time: 0 msec
;; SERVER: 172.16.0.23#53(172.16.0.23)
;; WHEN: Mon Jun 24 20:48:21 2013
;; MSG SIZE rcvd: 87
In short:
ip-10-125-90-172.ec2.internal.
ip-10-245-155-18.ec2.internal.
ip-10-31-197-102.ec2.internal.
domU-12-31-39-01-70-51.compute-1.internal.
domU-12-31-39-0B-B0-01.compute-1.internal.
domU-12-31-39-0C-B8-2E.compute-1.internal.
The ip-*.ec2.internal are clearly in US East. The domU-*.computer-1.internal also
look like US East although I'm not 100% sure what is the difference between the two.
The later ones look like HVM guests while the former ones are para-virtualized.
For comparison here are some internal addresses from my own EC2 systems:
- ip-10-228-237-207.eu-west-1.compute.internal - EU Ireland
- ip-10-248-19-46.us-west-2.compute.internal - US West Oregon
- ip-10-160-58-141.us-west-1.compute.internal - US West N. California
After relocating my audio files to an S3 bucket in US East the average call length dropped from 2:30 min to 2:00 min for the same IVR choices. This also minimizes the costs since Twilio charges per minute of incoming/outgoing calls. I think the audio quality has improved as well.
There are comments.
Even Facebook has Bugs
Here's a small but very visible UI bug in Facebook. While selecting for which applications to receive or not notifications there is a small progress bar image that appears left of the checkbox element. The trouble is this image displaces the checkbox and it appears to float right and left during the AJAX call. This is annoying.
There's an easy fix - either fix the progress image and checkbox positions so they don't move or place the image to the right.
In my practice these types of bugs are common. I usually classify them with High priority, because they tend to annoy the user and generate support calls or just look unprofessional.
There are comments.
Tip: Caching Large Objects for Celery and Amazon SQS
Some time ago a guy called Matt asked about passing large objects through their messaging queue. They were switching from RabbitMQ to Amazon SQS which has a limit of 64K total message size.
Recently I've made some changes in Difio which require passing larger objects as parameters to a Celery task. Since Difio is also using SQS I faced the same problem. Here is the solution using a cache back-end:
from celery.task import task
from django.core import cache as cache_module
def some_method():
... skip ...
task_cache = cache_module.get_cache('taskq')
task_cache.set(uuid, data, 3600)
handle_data.delay(uuid)
... skip ...
@task
def handle_data(uuid):
task_cache = cache_module.get_cache('taskq')
data = task_cache.get(uuid)
if data is None:
return
... do stuff ...
Objects are persisted in a secondary cache back-end, not the default one, to avoid
accidental destruction. uuid parameter is a string.
Although the objects passed are smaller than 64K I haven't seen any issues with this solution so far. Let me know if you are using something similar in your code and how it works for you.
There are comments.
Django Tips: Using Cache for Stateful HTTP
How do you keep state when working with a stateless protocol like HTTP? One possible answer is to use a cache back-end.
I'm working on an IVR application demo with Django and Twilio. The caller will make multiple choices using the phone keyboard. All of this needs to be put together and sent back to another server for processing. In my views I've added a simple cache get/set lines to preserve the selection.
Here's how it looks with actual application logic omitted
def incoming_call(request):
call_sid = request.GET.get('CallSid', '')
caller_id = request.GET.get('From', '')
state = {'from' : caller_id}
cache.set(call_sid, state)
return render(request, 'step2.xml')
def step2(request):
call_sid = request.GET.get('CallSid', '')
selection = int(request.GET.get('Digits', 0))
state = cache.get(call_sid, {})
state['step2_selection'] = selection
cache.set(call_sid, state)
return render(request, 'final_step.xml')
def final_step(request):
call_sid = request.GET.get('CallSid', '')
selection = int(request.GET.get('Digits', 1))
state = cache.get(call_sid, {})
state['final_step_selection'] = selection
Backend.process_user_selections(state)
return render(request, 'thank_you.xml')
At each step Django will update the current state associated with this call and return
a TwiML XML response. CallSid is a handy unique
identifier provided by Twilio.
I am using the latest django-s3-cache version which properly works with directories. When going to production that will likely switch to Amazon ElastiCache.
There are comments.
Nibbler - W3C Validator on Steroids
I've recently found Nibbler which gives you a report scoring the website out of 10 for various important criteria including accessibility, SEO, social media and technology.
The produced report is very interesting. Here is the report for this blog. There are things I definitely need to work on!
For comparison SofiaValley scores far beyond this blog. It is stronger in marketing and popularity but apparently weaker on the technology section. This is interesting!
PS: sorry for not producing technical content lately. I've been very busy with some current projects however I've got lots of ideas and topics to blog about. I hope to make it up to speed in the next few weeks. -- Alex
There are comments.
Personal Experience With Credit Card Fraud, Part 2
Earlier I wrote about my personal experience with credit card fraud. Now this issue is back again! Bad luck!
 Image CC-BY, Robert Scoble
Image CC-BY, Robert Scoble
Since my last card was re-issued I've used it only at Amazon Web Services, Google Apps and Globul. Nowhere else. According to the bank representative, who woke me up this morning, VISA has sent them a list of card numbers which need to be blocked immediately. The bank was vague about it but briefly mentioned some kind of a leak of VISA's card database.
Knowing how negligent payment operators can be I can easily accept this version. I'm wondering if there will be an official press release from VISA. Let me know if you hear about this!
There are comments.
Another Day At The Office
I just found Office Snapshots and they don't have any submissions from Bulgarian companies. No coincidence given the fact that many Bulgarian offices are years behind contemporary work space design and architecture.
 Image by egerbver
Image by egerbver
So I got an idea - start my own blog section on this topic. It would be interesting to see the spaces Bulgarian IT operates in. If the place is good - embrace it, if it sucks - despise it! What do you think?
Selection rules are as follow:
- Needs to be local Bulgarian company or a local branch of a foreign company;
- Can also be a start-up, an NGO or other organization;
- Business is in the field of IT and technology; Co-working spaces are exception;
Let me know which companies you want to see featured here! Can you arrange a visit for me - let me know!
There are comments.
Software Developer - Employee vs. Contractor, Part 1
 Image from Flickr.
Image from Flickr.
People tend to think I have a dream job, when I tell them I don't go to the office. I will tell you a story about working from home, being a remotee and not having a regular job. Welcome to the world of contracting and freelancing!
Terminology
Definitions taken from Wikipedia:
An employee contributes labor and expertise to an endeavor of an employer and is usually hired to perform specific duties which are packaged into a job. In most modern economies, the term "employee" refers to a specific defined relationship between an individual and a corporation, which differs from those of customer or client.
An independent contractor is a natural person, business, or corporation that provides goods or services to another entity under terms specified in a contract or within a verbal agreement.
A freelancer is somebody who is self-employed and is not committed to a particular employer long term. For the purpose of this article this is more or less the same as independent contractor but for a short-term project.
Most important of all is that a contractor or freelancer is a separate entity from the organization they work for.
How I became a contractor
5+ years ago I was an employee for Red Hat in Czech Republic, but didn't want to permanently live there for many reasons. During my time abroad I was a frequent traveler. I became comfortable working on the go and quite often my bosses didn't know where I was. Most importantly I made sure that location didn't matter!
After 1.5 years I left the company with an option to continue working for Red Hat Switzerland as a contractor. This is how I started working from home.
The dark side
Many people think working from home is easy. Many think being a contractor is better than being an employee. Many think being away from the office means you will work less. Many think you will make more money. Most people are wrong!
I will highlight the bad side of being a contractor before exposing you to the goodies. Read the next parts before even thinking to quit your job.
Payment
Contracting or freelancing is much more different than having a regular job. If you are lucky you will have a long-term project and have a somewhat regular income. On the other hand freelancing is usually the term used when working on smaller short-term projects. They are irregular, so is your income.
You need to plan in advance your expenses and make sure your income will cover them. This is a lot easier with long-term projects.
Also have in mind that contracts and projects can be delayed, terminated and postponed relatively easy on behalf of the customer and there isn't much you can do. At best they have already paid you for the job done until now and you are out looking for the next customer.
Longer-term contracts I've been working on had the option to terminate without any explanation given in two to four weeks. This is a risk you have to accept and have a contingency plan if your income depends on a single long-term project.
You either get paid by the hour or a lump sum on predefined milestone (e.g. half before, half after delivery). Either way you trade time for money which isn't optimal (same thing do employees btw). The best thing you can do is become an expert in your field and begin consulting. This is trading less time plus expertise for more money - much better.
I've been doing QA consulting for other smaller clients as odd jobs since forever. Some of the companies include Obecto and Opencode Systems. I also consult start-ups in the field of software testing and quality assurance.
UPDATE: at the end of 2015 I've been engaged more frequently with the engineering team at Tradeo, bringing them my QA expertise.
Employee benefits
Employees do get a lot of benefits:
- Christmas bonus
- Quarterly bonus if the company is doing well
- Performance oriented bonuses
- 25 days of paid vacation which increase the longer you work
- Extra health care
- Unemployment insurance, social securities, etc.
- Gym or other sport activities in the office
- Lunch or some snacks at the office
- Free car/cell phone/laptop, whatever
The bigger and more people oriented the company the more the benefits.
Contractors get nothing! Your contract payment is the only thing you get.
- If you want a vacation - you don't get paid!
- If you are sick - you don't get paid!
- If you need equipment - you have to buy it!
Get used to it and plan accordingly! That said I do use company sponsored MacBook Air and have a small budget for visiting some conferences abroad. In addition I attend lot more events on my own either by helping as volunteer or being a speaker at the event. I also have a personal unemployment and extra health care insurance, in fact several of them, just in case!
Taxes
In every country dealing with tax authorities is a hell. If you are a sole proprietor in Bulgaria chances are you will pay more taxes and social securities compared to being a company for the same revenue. If you can, always incorporate a company and contract through it. As of late all of my income goes through the company entity, I don't receive a single cent on my personal account. At the end of the year I pay myself a divident and use the money during the next year.
Find a good accountant (as much as you can afford though) and make sure they know everything about your income and activities. It's always better to hire an accounting company which can grant you some protection and liability against prosecution from tax authorities - for example if they get their calculation wrong. The extent of this should be written in a contract.
If necessary also hire a lawyer. If you deal with lots of paperwork and contracts (or NDAs) this is definitely a wise thing to do. Don't spare your money, spare yourself going to jail.
Work environment
Working from your bedroom sounds cool but it isn't. You need a quiet and comfortable place to work. Every-day house distractions are your worst enemy. You need much greater discipline compared to working in an office.
My own work environment has evolved to having the best
office chair
from Sweden, custom designed furniture to make my life easier
and access stuff more quickly, maximum usage of storage space at home,
SOHO network designed by myself so that every device has its place and plug,
backup Internet connections, etc. You need to invest in your work space to reap the benefits later.
I also follow a strict regime and have some fixed hours for work and no-work related activities. I split them between regular 9-5 business hours and evening/early morning to have more flexibility. Whatever the case you have to plan your activities and stick to your plan.
In the office there's always time for a coffee or some chit-chat. At home there is not. Every hour counts to your bonus so it is in your interest to log as many hours as possible and perform actual work during them. There are some freelance websites such as oDesk (which sucks btw) that require you to install software to monitor your screen, camera and keyboard in order the customer to see you were actually working.
Beware that there are physical limits which you can't break without putting your health at risk. I've tried working 200+ hours a month. It is doable once or twice a year when you have lot of things to do. But you can't do it all the time. I've tried, trust me.
Another important thing is the social element. Being out of the office minimizes the opportunities to socialize with co-workers or simply ask for help. A contractor needs some other way to compensate for this - being part of special interest groups, attending events and the like.
No customers risk
As with every business there is a risk of not having the right customers or not having them at all. There are several things you can do to minimize this risk:
- Be an expert in at least one field - this is your primary focus; For example: I'm an expert in Quality Engineering and Red Hat Enterprise Linux;
- Become very good professional in few more fields - mine are cloud computing, Python and Django and general open source programming;
- Grow your network of friends, co-workers, IT professionals and possible customers - you never know where the next customer will come from;
- Stay current with popular technologies (no need to be expert) so you can learn quickly if the need arises;
- Have some backup skills where there isn't much competition and customers will have a hard time finding the right guy. Also make sure you know where to find these customers. My skill is Pascal - its an old language but there are lots of legacy software which still needs to be maintained. Did you know you can even run COBOL in the cloud these days?
Diversify and be flexible - you have the opportunity to generate income from various sources - use it. I will tell you about mine in the next part of this article.
UPDATE:
I also strongly recommend the
The 4-Hour Workweek: Escape 9-5, Live Anywhere, and Join the New Rich
book by Tim Ferris. It is one of my all time favorite books and I try
to live by its rules as much as I can. I've also done a
book review here.
TO BE CONTINUED ... meanwhile use the comments below to ask me things you are curious about.
There are comments.
SofiaValley UI bug
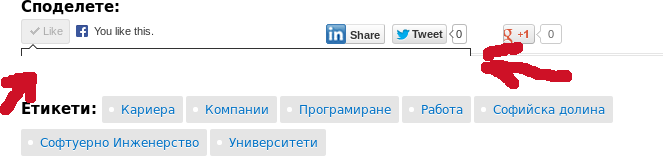
SofiaValley recently had a bug in their UI. As seen above when clicking the Like button the widget would overlap with other visual elements. At first this doesn't look like a big deal but it blocks the user from sharing the page via Facebook which is important for a blog.
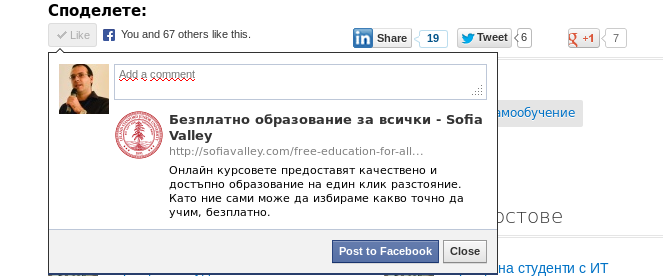
I have reported the error and it was fixed very quickly. +1 for SofiaValley.
Have you spotted any other interesting bugs? Let me know and they will be published here.
There are comments.
Call of the Open Source Guru
This week (28.05.2013) I've attended an interesting event, called “Call of the Guru”, that was held at the Faculty of Mathematics and Informatics at Sofia University. The idea was to get a group of IT professionals (gurus) to talk to young students on topics related to work, academia, start-up and open source.

 Images from RadoRado's Place and
SofiaValley.
Check their event reviews as well.
Images from RadoRado's Place and
SofiaValley.
Check their event reviews as well.
In another post I've already shared my thoughts on future IT jobs. Here I will talk about what open source means for students.
Why hack open source
That's the number one question students will ask. The answer is simple
It gives you experience and you become a hacker!
There is absolutely no way one could graduate in their early 20s, not work during study and have 3-5 years of experience as required by many job offers. Unless one hacks open source.
- Open source is real world, not a play project. There are many interesting problems to be solved; There's always work to be done;
- Complex software teaches you software design/architecture patterns;
- Larger projects like Linux distributions can also teach you about software release cycle and release processes;
- You work with a team, which drives you forward and you gain experience;
- You learn to be patient as your work is reviewed by others and mistakes pointed out;
- Larger projects use several different languages so you learn them; or alternatively hack on different projects;
- You communicate - via email and IRC mostly but that teaches you communication skills. To see the difference between how educated people talk and how politicians talk listen to this video;
- You make friends and connections which may benefit you later in your career;
- Many open source companies recruit right from the community. I know lots of people who landed their dream job by hacking for fun.
As a student, if you can afford not getting a job it's better to use your time on open source projects. This is what I did as a young student and a junior developer. The rest is history!
What to do
There are many things one can do in open source - write code, test software and find bugs, write automated test cases, translate to local languages, design user interfaces and project websites, maintain wiki articles, provide help to users on forums or IRC channels, help organize events, etc. All of this is respected in the community and gives credibility.
Where to start
If you haven't already read How To Become A Hacker by Eric Raymond you should do so right away. Then come back and finish this article.
For those who'd like to start coding but have no idea where to start take a look at OpenHatch.
OpenHatch is a non-profit dedicated to matching prospective free software contributors with communities, tools, and education.
If you still like to be a developer but don't feel confident enough to hack on the core of the project I'd recommend you start by writing automated test cases. Writing test cases doesn't require much previous experience in programming and lets you explore and learn the internals of the software you're testing. With that knowledge you will become more confident and start writing on the core features if you like. I am myself a QA but regularly contribute patches to software I test because I know how it works or why it doesn't and it's easy for me to fix it.
If you'd better start as a translator check Transifex. It's used by both commercial and open source entities and has become the de-facto standard in open source translation tools. Btw the entire Transifex company was build after trying to solve a particular problem in the Fedora Project and they are an open source company.
For general news about open source check OpenSource.com.
Have questions? I have answers
Don't hesitate to ask me anything about open source and/or how to get involved with it. I will gladly share my experience (learned the hard-way in the old days) or point you to other folks who may know more on the topic.
There are comments.
Why VMware Multi-Hypervisor Manager Architecture Is Wrong
Today I've visited the annual VMware Open House Event in Sofia. One of the sessions discussed their product vCenter Multi-Hypervisor Manager and the developers explained their architecture and technology behind it. I think they are wrong.
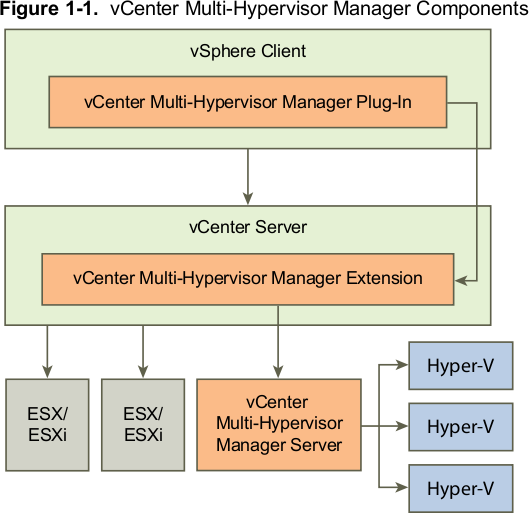 Image taken from product release notes.
Image taken from product release notes.
As shown above the purple-orange components are the MHM ones. They are designed as plug-ins to the vCenter product and can not function as stand alone products. vCenter MHM Server is responsible for communicating with 3rd party hypervisors and then talks back to the MHM Extension in vCenter which feeds the MHM Plug-In (the UI). I see three bad design decisions here:
1) The plugin architecture makes both the management layer and the UI a separate module. As was shown in a demo session the user can not manage/visualize ESX and Hyper-V hosts/VMs at the same time. They are managed and visualized in separate views. This leads to non uniform user experience. Not to mention both UIs are different because the supported hypervisor capabilities are different. -1 for user experience.
2) From what I understand both vCenter and MHM Extension provide API access. MHM one is not public yet. Customers are using this API to build their own scripts around the infrastructure. For a customer this means duplicating effort and maintaining scripts that talk to two separate APIs, although they will be very similar to one another. -1 for making it easy on the customer.
3) From development point of view the top two components are not necessary. They introduce extra development and management costs to the product. -1 for product maintainability.
The Alternative
One could design the same product in the fashion that libvirt does - abstract all hypervisor details and provide a common API to build applications against. In this case vCenter Server will be the application on top. This interface will also report hypervisor capabilities so that the UI will be disabled where appropriate.
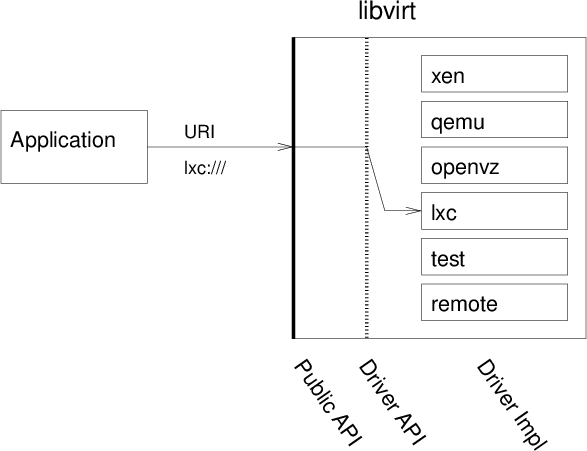 Image taken from http://libvirt.org/api.html
Image taken from http://libvirt.org/api.html
I think libvirt's approach is much cleaner and easier to maintain in the long term.
Indeed I've asked the question why not use libvirt - it already supports ESX and Hyper-V as well as bunch of other hypervisors. I didn't get a clear answer on that, just that the team was looking at it, evaluated libvirt but opted to go another way.
I still feel VMware has not learned how to do the open source dance as well as others do. What do you think?
There are comments.
Configuring Anonymous FTP Uploads On Red Hat Enterprise Linux 6
Install related packages and make configuration changes:
yum -y install vsftp policycoreutils-python
sed -i "s/#anon_upload_enable=YES/anon_upload_enable=YES/" /etc/vsftpd/vsftpd.conf
Configure writable directory for uploads:
mkdir /var/ftp/pub/upload
chgrp ftp /var/ftp/pub/upload
chmod 730 /var/ftp/pub/upload
Configure SELinux - this is MISSING from Red Hat's official docs:
setsebool -P allow_ftpd_anon_write=1
semanage fcontext -a -t public_content_rw_t '/var/ftp/pub/upload(/.*)'
chcon -t public_content_rw_t /var/ftp/pub/upload
Start the service:
chkconfig vsftpd on
service vsftpd start
There are comments.
IT Jobs Prediction: Quality Engineering, DevOps, Augmented Reality
Tomorrow I'm taking part in a discussion at Sofia University targeted towards young students. Speakers are well-known IT professionals and I'm honored to be invited.
One of the preliminary questions posted from students is
In which field to expect saturation of junior specialists in the next 5 years? Which technologies will see higher demand and which will not?
While I don't have a clear answer here are my favorites and comments. If I was a 20 year old student I would definitely be paying attention to these.
Quality Engineering, Quality Assurance, Test Automation
The more software gets written, the more critical the need to test it. In the past 6+ years I've been working in the field of QA and saw 5x rise in the workload and number of team members I've been working with. Traditionally Bulgaria is strong on the development side but lacks trained QA engineers. In the past I have also been approached by several foreign companies to train their QA staff and organize their QA processes. The situation here is not very different even today.
If you want a secure job become a top-notch QA with experience ranging from test automation, QA management, bug finding and all between. Strongly recommended is to get some industry recognized certificates (I don't have such for QA).
DevOps
Looks like DevOps is the new mantra. With advancement of cloud technologies and everything becoming as-a-service my gut is telling me that more and more organization will be switching to DevOps types of operations in an attempt to be faster, more cost effective and more agile. I myself am looking into this field.
While I haven't done a formal research to back-up my words I think DevOps will be a hot topic in the next 5 years until it becomes the norm. Acquire DevOps skills if you are particularly interested in working for start-ups or small engineering organizations serving large customer bases (e.g Disqus, GitHub, The Guardian).
Augmented Reality
AR is not a fiction anymore. We have everything we need to make use of it in everyday life and it's slowly becoming mainstream. If you are into maths, algorithms and research then this is your field. Couple with mobile devices, social networks, big data and cloud and you have a job for a life time.
What else?
I don't have a crystal ball to predict the future. It could be that my IT jobs predictions are totally wrong. Let me know what do you think. If you were in the beginning of your career which fields will you bet on?
There are comments.
Balkan Venture Forum Sofia Post-mortem

Balkan Venture Forum in Sofia is over. It's been two very exciting days, full of many interesting talks both on stage and off stage.
There were so many things that happened and so many new people I met that it will be hard to mention all of that in a single blog post. I just want to highlight the things I enjoyed the most.
Networking & pitching at the bar
I've been invited to BkVF long ago. However my initial intention was not to attend because this month proved to be very busy. I've changed my mind after Boyan Benev, one of the organizers invited me 10 days ago with an interesting proposal - distribute Difio's beer mats at the bar!

So I was there for the networking. As I used to say when people asked me if I was pitching
I am pitching at the bar!
Networking was very intensive both during the coffee breaks and cocktail and during the sessions. I've now got close to 50 new business cards in my pocket. I've met very cool guys and gals both developers and non-tech.
From the companies that were pitching in the main hall I particularly liked Imagga, Transmetrics and Kimola. Imagga was probably the most deep-tech/science oriented company at BkVF while Transmetrics and Kimola focus on cloud and big data solutions.
BlackBerry development session
OK, I'm not into mobile technology nor smart phones but that may change soon. BlackBerry had a strong presence and I was able to talk to some of their developer support folks. The OS of BlackBerry 10 is based on QNX kernel with multiple SDKs available to write apps. Most of all I like the fact that it is POSIX compliant with C/C++ native SDK available. Qt/QML is also available.
I'm particularly interested in how hard it will be to port some existing open source tools to BlackBerry. I'm talking Bash, Python and the command line tools I currently use on Linux. I'll be contacting them in the near future to get a device for testing and hacking and will keep you posted.
There are comments.
Linux and Python Tools To Compare Images
How to compare two images in Python? A tricky question with quite a few answers. Since my needs are simple, my solution is simpler!
 dif.io homepage before and after it got a G+1.
dif.io homepage before and after it got a G+1.
ImageMagic is magic
If you haven't heard of ImageMagic then you've been
living in a cave on a deserted island! The suite contains the compare command
which mathematically and visually annotates the difference between two images.
The third image above was produced with:
$ compare difio_10.png difio_11.png difio_diff.png
Differences are displayed in red (default) and the original image is seen in the
background. As shown, the Google +1 button and count has changed between the two
images. compare is a nice tool for manual inspection and debugging.
It works well in this case because the images are lossless PNGs and are regions of
screen shots where most objects are the same.
 Chestnuts I had in Rome. 100% to 99% quality reduction.
Chestnuts I had in Rome. 100% to 99% quality reduction.
As seen on the second image set only 1% of JPEG quality change leads to many small differences in the image, which are invisible to the naked eye.
Python Imaging Library aka PIL
PIL is another powerful tool for image manipulation. I googled around and found some answers to my original questions here. The proposed solution is to calculate RMS of the two images and compare that with some threshold to establish the level of certainty that two images are identical.
Simple solution
I've been working on a script lately which needs to know what is displayed on the screen and recognize some of the objects. Calculating image similarity is quite complex but comparing if two images are exactly identical is not. Given my environment and the fact that I'm comparing screen shots where only few areas changed (see first image above for example) led to the following solution:
- Take a screen shot;
- Crop a particular area of the image which needs to be examined;
- Compare to a baseline image of the same area created manually;
- Don't use RMS, use the image histogram only to speed up calculation.
I've prepared the baseline images with GIMP and tested couple of scenarios
using compare. Here's how it looks in code:
from PIL import Image
from dogtail.utils import screenshot
baseline_histogram = Image.open('/home/atodorov/baseline.png').histogram()
img = Image.open(screenshot())
region = img.crop((860, 300, 950, 320))
print region.histogram() == baseline_histogram
Results
The presented solution was easy to program, works fast and reliably for my use case. In fact after several iterations I've added a second baseline image to account for some unidentified noise which appears randomly in the first region. As far as I can tell the two checks combined are 100% accurate.
Field of application
I'm working on QA automation where this comes handy. However you may try some lame CAPTCHA recognition by comparing regions to a pre-defined baseline. Let me know if you come up with a cool idea or actually used this in code.
I'd love to hear about interesting projects which didn't get too complicated because of image recognition.
There are comments.
Dual Password Encryption With EncFS On Red Hat Enterprise Linux 6
This article is a step-by-step guide to using two passwords with EncFS. The primary password is required and may be used to secure all data; the secondary password is optional and may be stored on USB stick or other removable media and used to secure more sensitive data.
 The original article in Red Hat's Raleigh HQ!
The original article in Red Hat's Raleigh HQ!
This article has been originally written for and published by Red Hat Magazine. Here is a shortened version with updated commands for Red Hat Enterprise Linux 6.
Technical Information
EncFS provides an encrypted filesystem in user-space. EncFS provides security against offline attacks like a stolen notebook. EncFS works on files and directories, not an entire block device. It modifies file names and contents. The data is stored on the underlying filesystem and meta-data is preserved. File attributes such as ownership, modification date and permission bits are not encrypted and are visible to anybody. EncFS is acting like a translator between the user and the filesystem, encrypting and decrypting on the fly.
EncFS is easy to use and requires no special setup. A local user has to be in the ‘fuse’ group to use EncFS. It does not require ‘root’ privileges. EncFS can be used with secondary passwords. This could be used to store a separate set of files on the same encrypted filesystem. EncFS ignores files which do not decode properly, so files created with separate passwords will only be visible when the filesystem is mounted with the associated password. There is the option to read passwords from an external program or stdin (standard input). This option combined with custom scripting makes EncFS very flexible. By default, all FUSE based filesystems are visible only to the user who mounted them. No other users (including root) can view the filesystem contents.
Installing EncFS
Install fuse-encfs from EPEL:
# yum install fuse-encfs
Load the FUSE module:
# /sbin/modprobe fuse
And, finally, add any users that will use EncFS to group ‘fuse’:
# usermod -Gfuse jdoe
Using EncFS
Using EncFS does not differ from using any other filesystem. The only thing you need to do is to mount it somewhere and start creating files and directories under the mount point.
Warning: Use only absolute path names with EncFS!
Create working directories:
$ mkdir -p ~/encrypted ~/plain
plain/– looks like a normal directory. All files stored here look like normal files for the user who mounted this directory with EncFS. This acts like a virtual directory performing encryption and decryption.encrypted/– looks garbled. The actual data is stored here and is encrypted.
Now you can mount the new EncFS volume for the first time. This assumes a default configuration:
$ encfs /home/jdoe/encrypted /home/jdoe/plain
Creating new encrypted volume.
Please choose from one of the following options:
enter "x" for expert configuration mode,
enter "p" for pre-configured paranoia mode,
anything else, or an empty line will select standard mode.
?>
Standard configuration selected.
Configuration finished. The filesystem to be created has
the following properties:
Filesystem cipher: "ssl/aes", version 3:0:2
Filename encoding: "nameio/block", version 3:0:1
Key Size: 192 bits
Block Size: 1024 bytes
Each file contains 8 byte header with unique IV data.
Filenames encoded using IV chaining mode.
File holes passed through to ciphertext.
Now you will need to enter a password for your filesystem.
You will need to remember this password, as there is absolutely
no recovery mechanism. However, the password can be changed
later using encfsctl.
New Encfs Password: **********
Verify Encfs Password: **********
Create a file:
$ echo "some content" > ~/plain/file.one
Check contents in plain/:
$ ls -la ~/plain/
total 12
drwxrwxr-x. 2 jdoe jdoe 4096 May 14 21:31 .
drwx------. 6 jdoe jdoe 4096 May 14 21:29 ..
-rw-rw-r--. 1 jdoe jdoe 13 May 14 21:31 file.one
$ cat ~/plain/file.one
some content
Check what’s in encrypted/:
$ ls -la ~/encrypted/
total 16
drwxrwxr-x. 2 jdoe jdoe 4096 May 14 21:31 .
drwx------. 6 jdoe jdoe 4096 May 14 21:29 ..
-rw-rw-r--. 1 jdoe jdoe 1083 May 14 21:30 .encfs6.xml
-rw-rw-r--. 1 jdoe jdoe 21 May 14 21:31 Wq5NZ6q-yP-fYNWYsjzFhHf9
Warning: .encfs6.xml is a special file. When performing backups or restoring data,
make sure to keep this file!
Inspect the contents of encrypted file:
$ cat ~/encrypted/Wq5NZ6q-yP-fYNWYsjzFhHf9
���r�N�M���"p��
Unmount the filesystem and mount it again with another password:
$ fusermount -u ~/plain/
$ encfs --anykey /home/jdoe/encrypted /home/jdoe/plain
EncFS Password: *****
Caution: We are using the --anykey option to allow secondary passwords.
Check plain/ again. The directory is empty. Previous files were not decoded with the new password.
$ ls -la ~/plain/
total 8
drwxrwxr-x. 2 jdoe jdoe 4096 May 14 21:31 .
drwx------. 6 jdoe jdoe 4096 May 14 21:29 ..
Now create another file that will be in “hidden” mode:
$ echo "hidden contents" > ~/plain/file.two
Check again what’s in encrypted/. Both files are stored in the same directory:
$ ls -la ~/encrypted/
total 20
drwxrwxr-x. 2 jdoe jdoe 4096 May 14 21:35 .
drwx------. 6 jdoe jdoe 4096 May 14 21:29 ..
-rw-rw-r--. 1 jdoe jdoe 1083 May 14 21:30 .encfs6.xml
-rw-rw-r--. 1 jdoe jdoe 24 May 14 21:35 PfkZHs16YsKkznnTujaVsOuS
-rw-rw-r--. 1 jdoe jdoe 21 May 14 21:31 Wq5NZ6q-yP-fYNWYsjzFhHf9
Unmount and mount again using the first password:
$ fusermount -u ~/plain/
$ encfs --anykey /home/jdoe/encrypted /home/jdoe/plain
EncFS Password: **********
Inspect the contents of plain/ again. The second file was not decoded properly and is not shown:
$ ls -la ~/plain/
total 12
drwxrwxr-x. 2 jdoe jdoe 4096 May 14 21:35 .
drwx------. 6 jdoe jdoe 4096 May 14 21:29 ..
-rw-rw-r--. 1 jdoe jdoe 13 May 14 21:31 file.one
Summary
You have learned how to use encryption to protect your data. There is also a nice graphical application for using EncFS with KDE called K-EncFS. I'll be happy to answer any questions or comments.
There are comments.
Why Instagram Could Not Be Founded In Europe
Can a company like Instagram be founded in Europe and successfully exit for $ 1 billion? What do you think ?
This is precisely the question Bartłomiej Gola asked at WebIT BG last week. Here are his answers.
Theory says yes
In theory Europe is well suited for successful companies:
- We have talented software engineers and hackers;
- Great ideas are available everywhere;
- Funding is available - both early stage seed funding as well as VCs.
Forget about it
The short answer though is "forget about it"! There are several major differences between Europe and Silicon Valley which could break your start-up easily.
1) Europe doesn't have a strong branding with respect to technology. We are not perceived as a strong tech community which produces great things. Not to mention individual countries like Bulgaria. This means foreign investors are less likely to invest in European companies because they haven't heard about other successful companies coming from the region.
We as a community should work together and popularize the region (especially South Eastern Europe). I've seen this already in action. German cloud provider cloudControl has branded their website as "Proudly Made In Berlin".
2) The lack of reputation leads to the second issue - less followers on social media. Think about it! How many people in the US or Silicon Valley do you follow on Twitter? How many follow you back? How many of those who do, actually engage with what you share?
With some exceptions like my friend Bozhidar Batsov your social reach is quite limited when it comes to hi-tech users.
3) Less reputation plus less social reach means less buzz and less early adopters. Silicon Valley is a great place to generate buzz and find early adopters. Because of the software industry and many start-ups located in the area people generally have more open mindset and will try out new ideas, share valuable feedback, engage in social media and spread the word.
Early adopters are crucial for every start-up. And we don't have this mindset in Europe. I have seen it myself. From 400 friends and co-workers whom I've contacted via LinkedIn, half or more of them in Europe, only a few, not even a dozen have tried Difio. And we are talking about service from developers about developers. Nada.
I've tried another experiment as well. This time about non IT business. From around 100 female friends on Facebook around 10 followed a Facebook page which I've invited them to. The page is online ladies shoes shop.
What to do about it?
I don't have a clear answer here. We need to work hard and make Europe and Bulgaria well known in the software industry and start-up community. I encourage everyone to try, fail, try, fail and try until they succeed. And brag about what you do all the time.
This also prompted me another question. "How do companies in the Bulgarian start-up eco-system find their early adopters?" I think I'm gonna start a new blog category dedicated to this topic.
Is your company the next Instagram? Please use the comments and tell me.
There are comments.
The Best IT School in Bulgaria


What is Elsys?
Elsys (in Bulgarian TUES) is a technology school in Sofia. It is a subsidiary of Technical University of Sofia and this week they've celebrated their 25th anniversary. Elsys is not an ordinary school, they teach computer science to these young kids. And they do it pretty damn well. At the moment it's the best school to study IT (software, hardware, networks) in the country, contrary to what TU Sofia has become :(.
As one of the school sponsors I met lots of the students and want to show everyone else what they are doing. I have no doubts we will be hearing more about them in the future.
Robots first
So these boys and girls make robots. I was there when the first image was taken. It was this week in Thursday, April 25th at an educational fair. All visitors were fascinated by the robots and stopped by to watch and play with them. I personally wanted to see and play with the quadcopter shown above but it was not available that day.
While I was there, a guy approached the kids and said his company wants to fund development of another quadcopter. He wanted a bigger one, which is able to carry equipment for aerial photographs.
What shook me was that this is a rare occasion where a local business wants to fund R&D activities. Not to mentions these are school boys, not university students or research fellows where this is more common. And this happened days after the news about the quadcopter has been released in the social media.
Elsys also teaches Arduino classes where students play with home made robots. I personally have attended a robots competition held in the school where these small robots compete and sometimes fight with one another.
Did I mention they take part in First Lego League too? Just see the photos.
Open source
When not making robots students from Elsys hack open source and as it happened, one of them won the grand prize in Google Code-In 2012 (article in Bulgarian). For the last few years kids from Elsys are taking part in Google Code-In and according to the school website they've made $7300 from Google :). Over 40 boys and girls took part in the first edition of Google Code-In. That's 10% of all participants.
I'm sure Google and others were impressed by the fact so many good developers are coming from a single school. Aren't you?
Cisco Networking Academy
Yup, they have this too! Elsys teams have won top honors at 6 of the last 8 BANA-sponsored National Networking Competitions. Cisco themselves wrote an article about Elsys.
Want to help
As I said I'm a school sponsor. Probably the smallest one. If you want to help these kids and their school just let me know. I will put you in touch with the principal.
Alternatively you can donate your time and knowledge and start teaching an interesting class at school!
Or you can donate high quality IT books if you have such. Anything helps.
There are comments.
Page 13 / 16