A month ago I held a private discussional workshop for a friend's company in Sofia. With people at executive positions on the tech & business side we discussed some of their current problems with respect to delivering a quality product. Additionally I had a list of pre-compiled questions from members of the technical team, young developers, mostly without formal background in software testing! Some of the answers were inspired by The Art of Unit Testing by Roy Osherove hence the title!
Questions
Types of testing, general classification
There are many types of testing! Unit, Integration, System, Performance and Load, Mutation, Security, etc. Between different projects we may use the same term to refer to slightly different types of testing.
For example in Kiwi TCMS we generally test with a database deployed, hit the application through its views (backend points that serve HTTP requests) and assert on the response of these functions. The entire request-response cycle goes through the application together with all of its settings and add-ons! In this project we are more likely to classify this type of testing as Integration testing although at times it is more closer to System testing.
The reason I think Kiwi TCMS is more closer to integration testing is because we execute the tests against a running development version of the application! The test runner process and the SUT process are in the same memory space (different threads sometimes). In contrast full system testing for Kiwi TCMS will mean building and deploying the docker container (a docker compose actually), hitting the application through the layer exposed by Docker and asserting on the results. Here test runner and SUT are two distinctly separate processes. Here we also have email integration, GitHub and Bugzilla integration, additional 3rd party libraries that are installed in the Docker imaga, e.g. kerberos authentication.
In another example for
pelican-ab we mostly have unit
tests which show the SUT as working. However pelican-ab for a static HTML generator
and if failed miserably with DELETE_OUTPUT_DIRECTORY=True setting! The problem here is that
DELETE_OUTPUT_DIRECTORY doesn't control anything in the SUT but does control
behavior in the outer software! This can only be detected with integration tests,
where we perform testing of all integrated modules to verify the combined functionality,
see here.
As we don't depend on other services like a database I will classify this as pure integration testing b/c we are testing a plugin + specific configuration of the larger system which enforces more constraints.
My best advice is to:
1) have a general understanding of what the different terms mean in the industry 2) have a consensus within your team what do you mean when you say X type of testing and Y type of testing so that all of you speak the same language 3) try to speak a language which is closest to what the rest of the industry does, baring in mind that we people abuse and misuse language all the time!
What is unit testing
The classical definition is
A unit test is a piece of code (usually a method) that invokes another piece of code and checks the correctness of some assumptions afterwards. If the assumptions turn out to be wrong the unit test has failed. A unit is a method or function.
Notice the emphasis above: a unit is method or a function - we exercise these in unit tests. We should be examining their results or in a worse case the state of the class/module which contains these methods! Now also notice that this definition is different from the one available in the link above. For reference it is
42) Unit Testing
Testing of an individual software component or module is termed as Unit Testing.
Component can be a single class which comes close to the definition for unit testing but it can be several different classes, e.g. an authentication component handling several different scenarios. Modules in the sense of modules in a programming language almost always contain multiple classes and methods! Thus we unit test the classes and methods but we can rarely speak about unit testing the module itself.
OTOH the second definition gets the following correctly:
It is typically done by the programmer and not by testers, as it requires a detailed knowledge of the internal program design and code.
In my world, where everything is open source we testers can learn how the SUT and its classes and methods work and we can also write pure unit tests. For example in codec-rpm I had the pleasure to add very pure unit tests - call a function and assert on its result, nothing else in the system state changed (that's how the software was designed to work)!
Important:
Next questions ask about how to ... unit test ... and the term "unit test" in them is used wrongly! I will drop this and only use "test" to answer!
Also important - make the difference between unit type test and another type of test written with a unit testing framework! In most popular programming languages unit testing frameworks are very powerful! They can automatically discover your test suite (discovery), execute it (test runner), provide tooling for asserting conditions (equal, not equal, True, has changed, etc) and tooling for reporting on the results (console log, HTML, etc).
For example Kiwi TCMS is a Django application and it uses the standard test framework from Django which derives from Python's unittest! A tester can use pretty much any kind of testing framework to automate pretty much any kind of test! Some frameworks just make particular types of tests easier to implement than others.
How to write our tests without touching the DB when almost all business logic is contained within Active Record objects? Do we have to move this logic outside Active Record, in pure PHP classes that don't touch DB?
To answer the second part - it doesn't really matter. Separating logic from database is a nicer design in general (loosely coupled) but not always feasible. Wrt testing you can either mock calls to the database or perform your tests with the DB present.
For example Kiwi TCMS is a DB heavy applcation. Everything comes and goes to the
database, it hardly has any stand-alone logic. Thus the most natural way to test is together
with the database! Our framework provides tooling to load previously prepared test data
(db migrations, fixtures) and we also use factoryboy to speed up creation of ORM objects
only with the specific attributes that we need for the test!
Key here is speed and ease of development, not what is the best way in theory! In real-life testing there are hardly any best practices IMO. Testing is always very context dependent.
Is it good to test methods with Eloquent ORM/SQL statements and how to do it without a database?
Eloquent is the ORM layer for Laravel thus the question becomes the same as the previous one.! When the application is dependent on the DB, which in their case is, then it makes sense to use a database during testing!
For Feature tests isn't it better to to test them without a DB and b/c we have more business logic there. For them we must be certain that we call the correct methods?
Again, same as the previous one. Use the database when you have to! And two questions:
1) Does the database messes your testing up in some way? Does it prevent you from doing something? If yes, just debug the hell out of it, figure out what happens and then figure out how to fix it 2) What on Earth is we must be certain that we call the correct methods mean? (I am writing this as personal notes before the actual session took place). I suspect that this is the more general am I testing for the right thing question which inexperienced engineers ask. My rule of thumb is: check what do you assert on. Are you asserting that the record was created in the DB (so verifying explicitly permissions, DB setup, ORM correctness) or that the result of the operation mathes what the business logic expects (so verifying explicitly the expected behavior and implicitly that all the layers below managed to work so the data was actually written to disk)? At times both may be necessary (e.g. large system, lots of cachine, eventual consistency) but more often than not we need to actually assert on the business logic.
Example:
- technical validation: user tries to register an account, assert email was sent or
- business/behavior validation: user tries to register an account, after confirming their intent they are able to login
Optimization for faster execution time, parallel execution
Parallel testing is no, no, no in my book! If you do not understand why something is slow trowing more instances at it increases your complexity and decreases the things you do understand and subsequently are able to control and modify!
Check-out this excellent presentation by Emanuil Slavov at GTAC 2016. The most important thing Emanuil says is that a fast test suite is the result of many conscious actions which introduced small improvements over time. His team had assigned themselves the task to iteratively improve their test suite performance and at every step of the way they analyzed the existing bottlenecks and experimented with possible solutions.
The steps in particular are (on a single machine):
- Execute tests in dedicated environment;
- Start with empty database, not used by anything else; This also leads to adjustments in your test suite architecture and DB setup procedures;
- Simulate and stub external dependencies like 3rd party services;
- Move to containers but beware of slow disk I/O;
- Run database in memory not on disk because it is a temporary DB anyway;
- Don't clean test data, just trash the entire DB once you're done; Will also require adjustments to tests, e.g. assert the actual object is there, not that there are now 2 objects;
- Execute tests in parallel which should be the last thing to do!
- Equalize workload between parallel threads for optimal performance;
- Upgrade the hardware (RAM, CPU) aka vertical scaling; I would move this before parallel execution b/c test systems usually have less resources;
- Add horizontal scaling (probably with a messaging layer);
There are other more heuristical approaches like not running certain tests on certain branches and/or using historical data to predict what and where to execute. If you want to be fancy couple this with an ML algorithm but beware that there are only so many companies in the world that will have any real benefit from this. You and I probably won't. Read more about GTAC 2016.
Testing when touching the file system or working with 3rd party cloud providers
If touching the filesystem is occasional and doesn't slow you down ignore it! But also make sure you do have a fast disk, this is also true for DB access. Try to push everything to memory, e.g. large DB buffers, filesystem mounted in memory, all of this is very easy in Linux. Presumption here is that these are temporary objects and you will destroy them after testing.
Now if the actual behavior that you want to test is working with a filesystem (e.g. producing files on disk) or uploading files to a cloud provider there isn't much you can do about it! This is a system type of test where you rely on integration with a 3rd party solution.
For example for django-s3-cache you need to provide your Amazon S3 authentication tokens before you can execute the test suite. It will comminicate back and forth with AWS and possibly leave some artifacts there when it is done!
Same thing for lorax, where the essence
of the SUT is to build Linux images ready to be deployed in the cloud! Checkout the
PR above and click the View details button at the bottom right to see the various
test statuses for this PR:
- Travis CI - pylint + unit test + some integration type tests (cli talks to API server)
- very basic sanity tests (invoking the application cli via bash scripts). This hits the network to refresh with RPM package data from Fedora/CentOS repositories.
- Jenkins jobs for AWS, Azure, OpenStack, Vmware, other (tar, Docker, stand-alone KVM). These will run the SUT, get busy for about 10 minutes to compose a cloud image of the chosen format, extract the file to a local directory, upload to the chosen cloud vendor, spin up a VM there and wait for it to initialize, ssh to the VM and perform final assertions, e.g. validating it was able to boot as we expected it to. This is for x86_64 and we need it for Power, s390x and ARM as well! I am having troubles even finding vendors that support all of these environments! Future releases will support even more cloud environments so rinse and repeat!
My point is when your core functionality depends on a 3rd party provider your testing will depend on that as well. In the above example I've had the scenario where VMs in Azure were taking around 1hr to boot up. At the time we didn't know if that was due to us not integrating with Azure properly (they don't use cloud-init/NetworkManager but their own code which we had to install and configure inside the resulting Linux image) or because of infrastructure issues. It turned out Azure was having networking trouble at the time when our team was performing final testing before an important milestone. Sigh!
With what tests (Feature or Unit) should I start before refactoring?
So you know you are going to refactor something but it doesn't have [enough] tests? How do you start? The answer will ellude most developers. You do not start by defining the types of testing you should implement. You start with analyzing the existing behavior: how it works, what conditions it expects, what input data, what constraints, etc. This is very close to black-box testing techniques like decision tables, equivalence partitioning, etc with the added bonus that you have access to the source code and can more accurately figure out what is the actual behavior.
Then you write test scenarios (Given-When-Then or Actions 1, 2, 3 + expected results). You evaluate these scenarios if they encompass all the previously identified behavior and classify the risk assiciated with them. What if Scenario X fails after refactoring? Cloud be the code is wrong, could be the scenario is incomplete. How does that affect schedule, user experience, business risk (often money), etc.
Above is tipically the job of a true tester as illustrated by this picture from
Ingo Philipp, full presentation
here
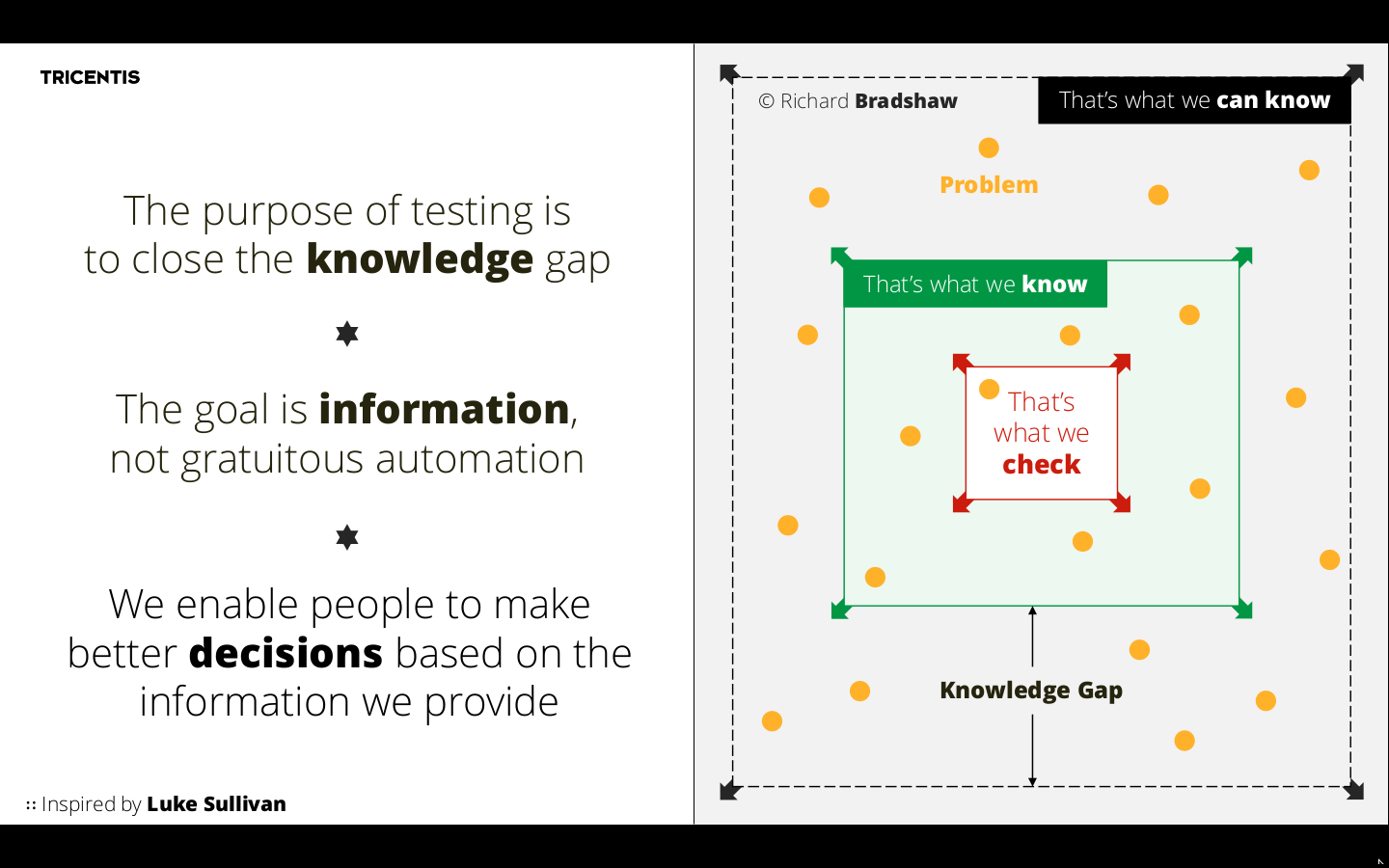
Then and only then you sit down and figure out what types of tests are needed to automate the identified scenarios, implement them and start refactoring.
What are inexperienced developers missing most often when writing tests? How to make my life easier if I am inexperienced and just starting with testing?
See the picture above! Developers, even experienced ones have a different mind set when they are working on fixing code or adding new features. What I've seen most oftenly is adding tests only for happy paths/positive scenarios and not spending enough time to evaluate and exercise all of the edge cases.
True 100% test coverage is impossible in practice and there are so many things that can go wrong. Developers are typically not aware of all that because it is tipically not their job to do it.
Also testing and development require different frame of mind. I myself am a tester but I do have formal education in software engineering and regularly contribute as developer to various projects (2000+ GitHub conributions as of late). When I revisit some tests I've written I often find they are pointless and incorrect. This is because at the time I've been thinking "how to make it work", not "how to test it and validate it actually works".
For an engineer without lots of experience in testing I would recommend to always start with a BDD exercise. The reason is it will put you in a frame of mind to think about expected behavior from the SUT and not think about implementation. This is the basis for asking questions and defining good scenarios. Automation testing is a means of expression, not a tool to find a solution to the testing problem!
Check-out this BDD experiment I did and also the resources here.
Inside-out(Classi approach) vs Outside-in(Mockist approach)? When and why?
These are terms associated with test driven development (TDD). A quick search reveals an excellent article explaining this question.
Inside Out TDD allows the developer to focus on one thing at a time. Each entity (i.e. an individual module or single class) is created until the whole application is built up. In one sense the individual entities could be deemed worthless until they are working together, and wiring the system together at a late stage may constitute higher risk. On the other hand, focussing on one entity at a time helps parallelise development work within a team.
This sounds to me is more suitable for less experienced teams but does require a strong senior personel to control the deliverables and steer work in the right direction.
Outside In TDD lends itself well to having a definable route through the system from the very start, even if some parts are initially hardcoded. The tests are based upon user-requested scenarios, and entities are wired together from the beginning. This allows a fluent API to emerge and integration is proved from the start of development. By focussing on a complete flow through the system from the start, knowledge of how different parts of the system interact with each other is required. As entities emerge, they are mocked or stubbed out, which allows their detail to be deferred until later. This approach means the developer needs to know how to test interactions up front, either through a mocking framework or by writing their own test doubles. The developer will then loop back, providing the real implementation of the mocked or stubbed entities through new unit tests.
I've seen this in practice in welder-web. This is the web UI for the above mentioned cloud image builder. The application was developed iteratively over the past 2 years and initially many of the screens and widgets were hard-coded. Some of the interactions were not even existing, you click on a button and it does nothing.
This is more of an MVP, start-up approach, very convenient for frequent product demos where you can demonstrate that some part of the system is now working and it shows real data!
However this requires a relatively experienced team both testers and developers and relatively well defined product vision. Individual steps (screens, interactions, components) may not be so well defined but everybody needs to know where the product should go so we can adjust our work and snap together.
As everything in testing the real answer is it depends and is often a mixture of the two.
What is the difference between a double, stub, mock, fake and spy?
These are classic unit testing terms defined by Gerard Meszaros in his book xUnit Test Patterns, more precisely in Test Double Patterns. These terms are somewhat confusing and also used interchangeably in testing frameworks so see below.
Background:
In most real-life software we have dependencies: on other libraries, on filesystems, on database, on external API, on another class (private and protected methods), etc. Pure unit testing (see definition at the top) is not concerned with these because we can't control them. Anytime we cross outside the class under test (where the method which is unit tested is defined) we have a dependency that we need to deal with. This may also apply to integration type tests, e.g. I don't want to hit GitHub every time I want to test my code will not crash when we receive a response from them.
From xUnit Test Patterns
For testing purposes we replace the real dependent component (DOC) with our Test Double. Depending on the kind of test we are executing, we may hard-code the behavior of the Test Double or we may configure it during the setup phase. When the SUT interacts with the Test Double, it won't be aware that it isn't talking to the real McCoy, but we will have achieved our goal of making impossible tests possible.
Example: testing discount algorithm
- Replace the method figuring out what kind of discount the customer is eligible to with a hard-coded test double: e.g. -30% and validate the final price matches!
- In another scenario use a second test double which applies 10% discount when you submit a coupon code. Verify the final price matches expectations!
Here we don't care how the actual discount percentage is determined. This is a dependency. We want to test that the discount is actually applied properly, e.g. there may be 2 or 3 different discounts and only 1 applies or no discount policy for items that are already on sale. This is what you are testing.
Important: when the applying algorithm is tightly coupled with parts of the system that select what types of discounts are available to the customer that means your code needs refactoring since you will be not able to crate a test double (or it will be very hard to do so).
A Fake Object is a kind of Test Double that is similar to a Test Stub in many ways including the need to install into the SUT a substitutable dependency but while a Test Stub acts as a control point to inject indirect inputs into the SUT the Fake Object does not. It merely provides a way for the interactions to occur in a self-consistent manner.
Variations (see here):
- Fake database;
- In-memory database;
- Fake web service (or fake web server in the case of Django);
- Fake service layer;
Use of a Test Spy is a simple and intuitive way to implement an observation point that exposes the indirect outputs of the SUT so they can be verified. Before we exercise the SUT, we install a Test Spy as a stand-in for depended-on component (DOC) used by the SUT. The Test Spy is designed to act as an observation point by recording the method calls made to it by the SUT as it is exercised. During the result verification phase, the test compares the actual values passed to the Test Spy by the SUT with the expected values.
Note: a test spy can be implemented via test double, exposing some of the functionality to the test framework, e.g. expose internal log messages so we can validate them or can be a very complex mock type of object.
From The Art of Unit Testing
A stub is a controllable replacement for an existing dependency (or collaborator) in the system. By using a stub, you can test your code without dealing with the dependency itself.
A mock object is a fake object in the system that decides whether the unit test has passed or failed. It does so by verifying whether the object under test (e.g. a method) interacted as expected with the fake object.
Stubs can NEVER fail a test! The asserts are aways against the class/method under test. Mocks can fail a test! We can assert how the class/method under test interacted with the mock.
Example:
When testing a registration form, which will send a confirmation email:
- Checking that invalid input is not accepted - will not trigger
send_mail()so we usually don't care about the dependency; - Checking valid input will create a new account in the DB - we stub-out
send_mail()because we don't want to generate unnecessary email traffic to the outside world. - Checking if a banned email address/domain can register - we mock
send_mail()so that we can assert that it was never called (together with other assertions that a correct error message was shown and no record was created in the database); - Checking that valid, non-banned email address can register - we mock
send_mail()and later assert it was called with the actual address in question. This will verify that the system will attempt to deliver a confirmation email to the new user!
To summarize: - When using mocks, stubs and fake objects we should be replacing external dependencies of the software under test, not internal methods from the SUT!. - Beware that many modern test framework use the singular term/class name Mock to refer to all of the things above. Depending on their behavior they can be true mocks or pure stubs.
More practical examples with code:
- Mocking Django AUTH_PROFILE_MODULE without a Database
- Bad Stub Design in DNF
- Bad Stub Design in DNF, Pt.2
- Beware of Double Stubs in RSpec
How do we test statistics where you have to create lots of records in different states to make sure the aggregation algorithms work properly?
Well there isn't much to do around this - create all the records and validate your queries! Here the functionality is mostly filter records from the database, group and aggregate them and display the results in table or chart form.
Depending on the complexity of what is displayed I may even go without actually automating this. If we have a representative set of test data (e.g. all possible states and values) then just make sure the generated charts and tables show the expected information.
In automation the only scenario I can think about is to re-implement the statistics
algorithm again! Doing a select() && stats() and assert stats(test_data) == stats()
doesn't make a lot of sense becase we're using the result of one method to validate
itself! It will help discover problems with select() but not with the actual
calculation!
Once you reimplement every stats twice you will see why I tend to go for manual testing here.
How to test various filters and searches which need lots of data?
First ask yourself the question - what do you need to test for?
- That all values from the webUI are passed down to the ORM
- That the ORM will actually return the records in question (e.g. active really means active not the opposite)
- which columns will be displayed (which is a UI thing)
For Kiwi TCMS search pages we don't do any kind of automated testing! These are very static HTML forms that pass their values to a JavaScript function which passes them to an API call and then renders the results! When you change it you have to validate it manually but nothing more really.
It is good to define test scenarios, especially based on customer bug reports but essentially you are checking that a number of values are passed around which either works or it doesn't. Not much logic and behavior to be tested there! Think like a tester, not like a developer!
How to test an API? Should we use an API spec schema and assert the server side and client side based on it?
This is generally a good idea. The biggest troubles with APIs is that they change without warning, sometimes in an incompatible way and clients are not aware of this. A few things you can do:
- Use API versioning and leave older versions arround for as long as necessary. Facebook for example keeps their older API versions around for several years.
- Use some sort of contract testing/API specification to validate behavior. I find value here to have a test suite which explicitly exercises the external API in the desired ways (full coverage of what the application uses) so it can detect when something breaks. If this is not 100% all the time it will become useless very quickly.
- Record and replay may be useful at scale, Twitter uses similar approach with anonimizing the actual values being sent around and also accounting for parameter types, e.g. an int X can receive only ints and if someone tries to send a string that was probably an error. Twitter however has access to their entire production data and can perform such kind of sampling.
What types of tests do QA people write? (I split this from the next question).
As should be evident by my many example nobody stops us from writing any kind of test in any kind of programming language. This only depends on personal skills and the specifics of the project we work on.
Please refer back to the codec-rpm, lorax and welder-web projects. These are components from a larger product named Composer which builds Linux cloud images.
welder-web is the front-end which integrates with Cockpit. This is written with React.js, includes some component type tests (I think close to unit tests but I haven't worked on them), end-to-end test suite (again JavaScript) similar to what you do with Selenium - fire up the browser and click on widgets.
lorax is a Python based backend with unit and integration tests in Python. I mostly work on testing the resulting cloud images which uses a test framework for Bash script, ansible, Docker and a bunch of vendor specific cli/api tools.
codec-rpm is smaller component from another backend called BDCS which is written in Haskell. As I showed you I've done some unit tests (and bug fixes even) and for bdcs-cli I did work on similar cloud image tests in bash script. This component is now frozen but when/if it picks up all the existing bash scripts will need to be ported plus any unit tests which are missing will have to be reimplemented in Haskell. Whoever on the team is free will get to do it.
At the very beginning we used to have a 3rd backend written in Rust but that was abandoned relatively quickly.
To top this off a good QE person will often work on test related tooling to support their team. I personally have worked on Cosmic-Ray - mutation testing tool for Python used by Amazon and others, I am the current maintainer of pylint-django - essentially a developer tool but I like to stretch its usage with customized plugins and of course Kiwi TCMS which is a test management tool.
How do they (testers) know what classes I am going to create so they are able to write tests for them beforehand?
This comes from test driven development practices. In TDD (as everywhere in testing) you will start with analisys what components are needed and how they will work. Imagine that I want you to implement a class that represents a cash-desk which can take money and store them, count them, etc. Imagine this is part of a banking application where you can open accounts, transfer money between them, etc.
With TDD I start by implementing tests for the desired behavior. I will import solution
and I will create an object from the Bill class to represent a 5 BGN note.
I don't care how you want to name your classes! The tests serve to enforce the interface
I need you to implement: module name, classes in the module, method names, behavior.
Initially in TDD the tests will fail. Once functionality becomes to be implemented piece by piece tests will start passing one by one! In TDD testers don't know, we expect developers to do something otherwise tests fail and you can't merge!
In practice there is a back-and-forth process!
The above scenario is part of my training courses where I give students homework assignments and I have already provided automated test suites for the classes and modules they have to implement. Once the suite reports PASS I know the student has at least done good enough implementation to meet the bare minimum of requirements. See an example for the Cash-Desk and Bank-Account problems at https://github.com/atodorov/qa-automation-python-selenium-101/tree/master/module04
How to test functionality which is date/time dependent?
For example a certain function should execute on week days but not on the weekend. How do we test this? Very simple, we need to time travel, at least out tests do.
Check-out php-timecop and this introductory article. Now that we know what stubs are we simply use a suitable library and stub out date/time utilities. This essentially gives you the ability to freeze the system clock or time travel backwards and forwards in time so you can execute your tests in the appropriate environment. There are many such time-travel/time-freeze libraries for all popular programming languages.
Given the two variations of the method below:
public function updateStatusPaid()
{
$this->update([
'date_paid' => now(),
'status' => 'paid'
]);
}
public function updateStatusPaid()
{
$this->date_paid = now();
$this->status = 'paid';
$this->save();
}
How do we create a test which validates this method without touching the database? Also we want to be able to switch between method implementations without updating the test code!
Let's examine this in details. Both of these methods change field values for the $this object
and commit that to storage! There is no indication what happened inside other than the
object fields being changed in the underlying storage medium.
Options:
1) Mock the save() method or spy the entire storage layer. This will give you
faster speed of execution but more importantly will let you examine the values before
they leave the process memory space. Your best bet here is replacing the entire
backend portion of the ORM layer which talks to the database. Drawback is that data may not be persistent
between test executions/different test methods (depending on how they are executed and how
the new storage layer works) so chained tests, which depend on data created by other tests
or other parts of the system may break.
2) Modify your method to provide more information which can be consumed by the tests. This is
called engineering for testability. The trouble with this method is that it doesn't
expose anything to the outside world so the only way we can check that something has
changed is to actually fetch it from storage and assert that it is different.
3) Test with the database included. The OP presumes touching a database during testing is
a bad thing. As I've already pointed out this is not necessarily the case. Unless your data
is so big that it is spread around cluster nodes in several shards using a database for
testing is probably the easiest thing you can do.
Now to the second part of the question: if your test is not tightly coupled with the method implementation then it will not need to be changed once you change the implementation. That is if you are asserting on independent system state then you should be fine.
Current problems
This is a list of problems we discussed, my views on them and similar items I've seen in the past. They are valid across the board for many types of companies and teams and my only recommendation here is to analyze the root of your problems and act to resolve them. IMO a lot of the times the actual problems stem from not understanding the roots of what we are trying to validate, not from technological limitations.
Background:
Company is delivering a digital product, over e-mail, without a required login procedure. There are event ticket sites which work like this.
Problem: email delivery fails, customer closes their browser and they can't get back to what they paid for. Essentially customers locks themselves out of the product they paid for.
This is UX problem. Email is inherently unreliable and it can break at many steps along the way. The product is not designed to be fault tolerant and to provide a way for the customer to retrieve their digital products. Options include:
- Browser cookies to remember orders in the last X days
- Well designed error/warning messages about possible data loss
- Require login (email or social) or other means of backup delivery (mobile phone, second email address, etc)
- Login is sometimes required by regulatory bodies (KYC practices) and is also a good starting point for additional marketting/relationship building activities
- Monitoring of email delivery providers and their operation. This is a business critical functionality so it must be treated like that.
Product needs enough input data from customer to produce a deliverable. Problem: Sometimes enough may not be enough, that is the backend algorithm thinks it hass everything and then it runs into some corner case from which it can't recover and is not able to deliver its results to the customer.
I see this essentially as an UX problem:
- Ask customer for more info at the beginning - annoying, slows down initial product adoption, may break the conversion funnel;
- Calculate what we can and randomly pick options from DB (curated or based on statistics) and present them to customer;
- Previous point + allow the customer to proceed or go back and refine the selection which was automatically made for them - this is managing the UX experience around the technological limitations
Infrastructure problems: site doesn't open (not accessible for some reason), big email queue, many levels of cache (using varnish)
Agressive monitoring of all of these items with alerts and combined charts. This is business critical functionality and we need to always know what is the status of it. If you want to be fancy couple this with an ML/AI algorithm which will predict failures in advance so you can be on alert before that happens.
More importantly each problem in production must be followed by a post-mortem session (more on that later).
Integration with payment processors: how do you test this in production ?
Again agressive monitoring when/if these integrations are up and running, then:
Design a small test suite which goes directly on the website and examines if all payment options are available. This will catch scenarios where you claim PayPal is supported but for some reason the form didn't load. The problem may not be on your side! Check preferences per country (may have been editted by admin on the backend), make sure what you promised is always there.
I've used similar approach in a trading startup. We run the suite once every hour directly agains prod. Results were charted in Grafana together with the rest of the monitoring metrics. In the first two days we found that the HTML form provided by the payment processor was changing all the time - this was supposed to be stable. In the first week we discovered the payment processor had issues on their own and were down for couple of hours during the night our time zone.
There isn't much you can do when you rely on 3rd party services but you can either - cache and retry later, masking the backend failures from the user at your own risk (payment may not be authorized later) - do not accept payment or at least warn the customer if you are seeing/predicting 3rd party issues
Problem: customers cancelling their payments after product was received
Yes, in many countries you can do so many days after you paid and got access to something. I have done so myself after non-delivery of items.
In case this is deliberate action from the customer there isn't much you can do. In case it is because they were frustrated due to problems overzealous monitoring and communicating back to the customers will probably help.
Localization problems, missing translations, UI doesn't look good, missing images
Unless your test team speaks the language they can't understand shit. Best options IMO:
- Allow translator team to preview their work before it is comitted to the current version; A simple staging server will work for this. This is easy to integrate with any translation system;
- Use machine checks: missing format strings, unfilled data (e.g. missing translations), 404 URLs. This is cheap to execute and can be done on Save and provide immediate feedback;
- Many systems provide the option to Review & Approve the work of another peer;
- Some visual testing tools (I don't have much experience here but I know they exist) which will detect strings that are too long and do not fit inside buttons and other widgets. This is more in the category of visual layout testing.
Problem: on mobile version, after new feature was added the 'Buy' button was overlayed by another widget and was not visible
This means that:
- previously it was not defined what testing will be performed for the new feature;
- also that this 'Buy' button was not considered business critical functionality, which it is;
- the person who signed-off on this page was careless;
Test management tools like Kiwi TCMS can help you with organizing and documenting what needs to be tested. However, regardless of the system used, everything starts with identifying which functionality is critical and must always be present! This is the job of a tester!
Once identified as critical you could probably use some tools for visual comparison to make sure this button is always available on this (other) pages. Again a person must identify all the possible interactions we want to check for.
Problem: we released at 18:30 on Friday and went home. We discovered email delivery was broken at 10:00 the next day
Obviously this wasn't well tested since it broke. The root cause must be analized and a test for it added.
Also we are missing a minitoring metric here. If you are sending lots of emails then a drop under, say 50K/hour probably means problems! What's the reason the existing monitoring tools didn't trigger? Investigate and fix it.
Last - do not push & throw over the fence. This is the silo mentality of the past. A small team can allow itself to make these mistakes just a few times, then comapny goes out of business and the people who didn't care enough to resolve the problems go out of a job.
Make a policy which gives you enough time to monitor production and revert in case of problems. There are many reasons lots of companies don't release on Friday (while others do). The point here is to put the policy and entire machinery in place so you can deal with problems when they arise. If you are not equipped to deal with these problems on late Friday night (or any other day/night of the week) you should not be making releases then.
Problem: how do we follow-up after a blunder?
In any growing team or company, especially a startup there is more demand to work on new features than maintain existing code, resolve problems or work on non-visible items like testing and monitoring which will help you the next time there are problems.

An evaluation framework like the Swiss cheese model is a good place to start. Prezi uses it extensively. Various sized holes are the different root causes which will lead to a problem:
- missing tests
- undocumented release procedure
- merged without code review
- incomplete feature specification
- too much work, task overload
The cheese layers can be both technical and organizational. One of them can be the business takeholders organization: wanting too much, not budgeting time for other tasks, tight marketting schedule, etc.
Once a post-mortem is held and the issues at hand analyzed you need to come up with a plan of action. These are your JIRA tickets about what to do next. Some will have immediate priority others will be important 1 year from now. Once the action items are entered into your task tracking software the only thing left to do is priritizing them accordingly.
Important: tests, monitoring, even talking about a post-mortem and other seemingly non-visible tasks are still important. If the business doesn't budget time for their completion it will ultimately fail! You can not sustain adding new features quickly for an extended period of time without taking the time to resolve your architecture, infrastructure, team and who knows what other issues.
Time and resources should be evaluated and assigned according to the importance of the task and the various risks assiciated with it. This is no different from when we do planning for new features. Consider having the ability to analyze, adapt and resolve problems as the most important feature of your organization!
Comments !