Testing Data Structures in Pykickstart
When designing automated test cases we often think either about increasing coverage or in terms of testing more use-cases aka behavior scenarios. Both are valid approaches to improve testing and both of them seem to focus around execution control flow (or business logic). However program behavior is sometimes controlled via the contents of its data structures and this is something which is rarely tested.
In this comment Brian C. Lane and Vratislav Podzimek from Red Hat are talking about a data structure which maps Fedora versions to particular implementations of kickstart commands. For example
class RHEL7Handler(BaseHandler):
version = RHEL7
commandMap = {
"auth": commands.authconfig.FC3_Authconfig,
"authconfig": commands.authconfig.FC3_Authconfig,
"autopart": commands.autopart.F20_AutoPart,
"autostep": commands.autostep.FC3_AutoStep,
"bootloader": commands.bootloader.RHEL7_Bootloader,
}
In their particular case the Fedora 21 logvol implementation introduced the
--profile parameter but in
Fedora 22 and Fedora 23 the logvol command mapped to the Fedora 20 implementation and the
--profile parameter wasn't available. This is unexpected change in program behavior
although the logvol.py and handlers/f22.py files have
99% and 100% code coverage.
This morning I did some coding and created an automated test for this problem. The test iterates over all command maps. For each command in the map (that is data structure member) we load the module which provides all possible implementations for that command. In the loaded module we search for implementations which have newer versions than what is in the map, but not newer than the current Fedora version under test. With a little bit of pruning the current list of offenses is
ERROR: In `handlers/devel.py` the "fcoe" command maps to "F13_Fcoe" while in
`pykickstart.commands.fcoe` there is newer implementation: "RHEL7_Fcoe".
ERROR: In `handlers/devel.py` "FcoeData" maps to "F13_FcoeData" while in
`pykickstart.commands.fcoe` there is newer implementation: "RHEL7_FcoeData".
ERROR: In `handlers/devel.py` the "user" command maps to "F19_User" while in
`pykickstart.commands.user` there is newer implementation: "F24_User".
ERROR: In `handlers/f24.py` the "user" command maps to "F19_User" while in
`pykickstart.commands.user` there is newer implementation: "F24_User".
ERROR: In `handlers/f22.py` the "logvol" command maps to "F20_LogVol" while in
`pykickstart.commands.logvol` there is newer implementation: "F21_LogVol".
ERROR: In `handlers/f22.py` "LogVolData" maps to "F20_LogVolData" while in
`pykickstart.commands.logvol` there is newer implementation: "F21_LogVolData".
ERROR: In `handlers/f18.py` the "network" command maps to "F16_Network" while in
`pykickstart.commands.network` there is newer implementation: "F18_Network".
The first two are possibly false negatives or related to the naming conventions used
in this module. However the rest appear to be legitimate problems. The user command
has introduced the --groups parameter in Fedora 24 (devel is Fedora 25 currently) but the
parser will fail to recognize this parameter. The logvol problem is recognized as well
since it was never patched. And the Fedora 18 network command implements a new property called
hostname which has probably never been available to be used.
You can follow my current work in PR #91 and happy testing your data structures.
There are comments.
Don't Upgrade Galaxy S5 to Android 6.0
Samsung is shipping out buggy software like a boss, no doubt about it. I've written a bit about their bugs previously. However I didn't expect them to release Android 6.0.1 and render my Galaxy S5 completely useless with respect to the feature I use the most.

Tell me the weather for Brussels
So on Monday I've let Android upgrade to 6.0.1 to be completely surprised
that the lockscreen shows the weather report for Brussels, while
I'm based in Sofia. I've checked AccuWeather (I did go to
Brussels earlier this year)
but it displayed only Sofia and Thessaloniki. To get rid of this widget
go to Settings -> Lockscreen -> Additional information and turn it off!
I think this weather report comes from GPS/Location based data, which I have turned off by default but did use a while back ago. After turning the widget off and back on it didn't appear on the lockscreen. I suspect they fall back to showing the last good known value when data is missing instead of handling the error properly.
Apps are gone
Some of my installed apps are missing now. So far I've noticed that the Gallery and S Health icons have disappeared from my homescreen. I think S Health came from Samsung's app store but still they shouldn't have removed it silently. Now I wonder what happened to my data.
I don't see why Gallery was removed though. The only way to view pictures is to use the camera app preview functionality which is kind of grose.
Grayscale in powersafe mode is gone
The killer feature on these higher end Galaxy devices is the Powersafe mode and Ultra Powersafe mode. I use them a lot and by default have my phone in Powersafe mode with grayscale colors enabled. It is easier on the eyes and also safes your battery.
NOTE: grayscale colors don't affect some displays but these devices use AMOLED screens which need different amounts of power to display different colors. More black means less power required!
After the upgrade grayscale is no more. There's not even an on/off switch.
I've managed to find a workaround though. First you need to enable developer mode
by tapping 7 times on About device -> Build number. Then go to
Settings -> Developer options, look for the Hardware Accelerated Rendering
section and select Simulate Color Space -> Monochromacy! This is a bit ugly
hack and doesn't have the convenience of turning colors on/off by tapping
the quick Powersafe mode button at the top of the screen!
It looks like Samsung didn't think this upgrade well enough or didn't test it well enough ? In my line of work (installation and upgrade testing) I've rarely seen such a big blunder. Thanks for reading and happy testing!
There are comments.
How To Hire Software Testers, Pt. 3
In previous posts (links below) I have described my process of interviewing QA candidates. Today I'm quoting an excerpt from the book Mission: My IT career(Bulgarian only) by Ivaylo Hristov, one of Komfo's co-founders.

He writes
Probably the most important personal trait of a QA engineer is to
be able to think outside given boundaries and prejudices
(about software that is). When necessary to be non-conventional and
apply different approaches to the problems being solved. This will help
them find defect which nobody else will notice.
Most often errors/mistakes in software development are made due to
wrong expectations or wrong assumptions. Very often this happens because
developers hope their software will be used in one particular way
(as it was designed to) or that a particular set of data will be returned.
Thus the skill to think outside the box is the most important skill
we (as employers) are looking to find in a QA candidate. At job interviews
you can expect to be given tasks and questions which examine those skills.
How would you test a pen?
This is Ivaylo's favorite question for QA candidates. He's looking for attention to details and knowing when to stop testing. Some of the possible answers related to core functionality are
- Does the pen write in the correct color
- Does the color fades over time
- Does the pen operate normally at various temperatures? What temperature intervals would you choose for testing
- Does the pen operate normally at various atmospheric pressure
- When writing, does the pen leave excessive ink
- When writing, do you get a continuous line or not
- What pressure does the user need to apply in order to write a continuous line
- What surfaces can the pen write on? What surfaces would you test
- Are you able to write on a piece of paper if there is something soft underneath
- What is the maximum inclination angle at which the pen is able to write without problems
- Does the ink dry fast
- If we spill different liquids onto a sheet of paper, on which we had written something, does the ink stay intact or smear
- Can you use pencil rubber to erase the ink? What else would you test
- How long can you write before we run out of ink
- How fat is the ink line
Then Ivaylo gives a few more non-obvious answers
- Verify that all labels on the pen/ink cartridge are correctly spelled and how durable they are (try to erase them)
- Strength test - what is the maximum height you can drop the pen from without breaking it
- Verify that dimensions are correct
- Test if the pen keeps writing after not being used for some time (how long)
- Testing individual pen components under different temperature and atmospheric conditions
- Verify that materials used to make the pen are safe, e.g. when you put the pen in your mouth
When should you stop ? According to the book there can be between 50 and 100 test cases for a single pen, maybe more. It's not a good sign if you stop at the first 3!
If you want to know what skills are revealed via these questions please read my other posts on the topic:
Thanks for reading and happy testing!
There are comments.
Capybara's find().click doesn't always fire onClick
Recently I've observed a strange behavior in one of the test suites I'm
working with - a test which submits a web form appeared to fail at a rate
between 10% and 30%. This immediately made me think there is some kind of
race-condition but it turned out that Capybara's find().click method
doesn't always fire the onClick event in the browser!
The test suite uses Capybara, Poltergeist and PhantomJS. The element we click on is an image, coupled to a hidden check-box underneath. When the image is clicked onClick is fired and the check-box is updated accordingly. In the failed cases the underlying check-box wasn't updated! Searching the web reveals a similar problem described by Alex Okolish so we've tried his solution:
div.find('.replacement', visible: true).trigger(:click)
How to Test
The failure behavior being somewhat flaky I've opted for running the test multiple times and see what happens when it fails. Initially I've executed the test in batches of 10 and 20 repetitions to get a feeling of how often does it fail before proceeding with debugging. Debugging was done by logging variables and state on the console and repeating multiple times. Once a possible solution was proposed we've run the tests in batches of 100 repetitions and counted how often they failed.
At the end, when Alex's solution was discovered we've repeated the testing around 1000 times just to make sure it works reliably. So far this has been working without issues!
I've spent around a week working on this together with a co-worker
and we didn't really want to spend more time trying to figure out
what was going wrong with our tools. Once we saw that trigger does
the job we didn't continue debugging Capybara or PhantomJS.
There are comments.
DEVit Conf 2016
It's been another busy week after DEVit conf took place in Thessaloniki. Here are my impressions.

Pre-conference
TechMinistry is Thessaloniki's hacker space which is hosted at a central location, near major shopping streets. I've attended an Open Source Wednesday meeting. From the event description I thought that there was going to be a discussion about getting involved with Firefox. However that was not the case. Once people started coming in they formed organic groups and started discussing various topics on their own.
I was also shown their 3D printer which IMO is the most precise of 3D printers I've seen so far. Imagine what it would be like to click Print, sometime in the future, and have your online orders appear on your desk over night. That would be quite cool!
I've met with Christos Bacharakis, a Mozilla representative for Greece, who gave me some goodies for my students at HackBulgaria!
On Thursday I spent the day merging pull requests for MrSenko/pelican-octopress-theme and attended the DEVit Speakers dinner at Massalia. Food and drinks were very good and I even found a new recipe for mushrooms with ouzo, of which I think I had a bit too many :).
I was also told that "a full stack developer is a developer who can introduce a bug to every layer of the software stack". I can't agree more!
DEVit
The conference day started with a huge delay due to long queues for registration. The fist talk I attended, and the best one IMO was Need It Robust? Make It Fragile! by Yegor Bugayenko (watch the video). There he talked about two different approaches to writing software: fail safe vs. fail fast.
He argues that when software is designed to fail fast bugs are discovered earlier in the development cycle/software lifetime and thus are easier to fix, making the whole system more robust and more stable. On the other hand when software is designed to hide failures and tries to recover auto-magically the same problems remain hidden for longer and when they are finally discovered they are harder to fix. This is mostly due to the fact that the original error condition is hidden and manifested in a different way which makes it harder to debug.
Yegor made several examples, all of which are valid code, which he considers bad practice. For example imagine we have a function that accepts a filename as parameter:
def read_file_fail_safe(fname):
if not os.path.exists(fname):
return -1
# read the file, do something else
...
return bytes_read
def read_file_fail_fast(fname):
if not os.path.exists(fname):
raise Exception('File does not exist')
# read the file, do something else
return bytes_read
In the first example read_file_fail_safe returns -1 on error. The trouble is
whoever is calling this method may not check for errors thus corrupting the
flow of the program further down the line. You may also want to collect metrics and
update your database with the number of bytes processed - this will totally
skew your metrics. C programmers out there will quickly remember at least
one case when they didn't check the return code for errors!
The second example read_file_fail_fast will raise an exception the moment
it encounters a problem. It's not its fault that the file doesn't exist and
there's nothing it can do about it, nor is its job to do anything about it.
Raising an exception will surface back to the caller and they will be notified
about the problem, taking appropriate actions to resolve it.
Yegor was also unhappy that many books teach fail safe and even IDEs (for Java) generate fail safe boiler-plate code (need to check this)! Indeed it is me who asks the first question Are there any tools to detect fail safe code patterns? and it turns out there aren't (for the majority of cases that is). If you happen to know such a tool please post a link in the comments below.
I was a bit disappointed by the rest of the talks. They were all high-level overviews IMO and didn't go deep technical. Last year was better. I also wanted to attend the GitHub Patchwork workshop but looking at the agenda it looked like this is for users who are starting with git and GitHub (which I'm not).
The closing session of the day was "Real time front-end alchemy, or: capturing, playing, altering and encoding video and audio streams, without servers or plugins!" by Soledad Penades from Mozilla. There she gave a demo about the latest and greatest in terms of audio and video capturing, recording and mixing natively in the browser. This is definitively very cool for apps in the audio/video space but I can also imagine an application for us software testers.
Depending on computational and memory requirements you should be able to record everything the user does in their browser (while on your website) and send it back home when they want to report an error or contact support. Definitely better than screenshots and having to go back and forth until the exact steps to reproduce are established.
There are comments.
Changing Rails consider_all_requests_local in RSpec fails
As many others I've been trying to change
Rails.application.config.consider_all_requests_local and
Rails.application.config.action_dispatch.show_exceptions inside my
RSpec tests in order to test custom error pages in a Rails app. However this
doesn't work. My code looked like this
feature 'Exceptions' do
before do
Rails.application.config.action_dispatch.show_exceptions = true
Rails.application.config.consider_all_requests_local = false
end
This works only if I execute exceptions_spec.rb alone. However when something
else executes before that it fails. The config values are
correctly updated but that doesn't seem to have effect.
The answer and solution comes from Henrik N.
action_dispatch.show_exceptions gets copied and cached in Rails.application.env_config, so even if you change Rails.application.config.action_dispatch.show_exceptions in this before block the value isn't what you expect when it's used in ActionDispatch::DebugExceptions.
In fact DebugExceptions uses env['action_dispatch.show_exceptions']. The
correct code should look like this
before do
method = Rails.application.method(:env_config)
expect(Rails.application).to receive(:env_config).with(no_args) do
method.call.merge(
'action_dispatch.show_exceptions' => true,
'action_dispatch.show_detailed_exceptions' => false,
'consider_all_requests_local' => false
)
end
end
This allows the test to work regardless of the order of execution
of spec files. I don't know why but I also had to leave
show_detailed_exceptions otherwise I wasn't getting the desired results.
There are comments.
Mismatch in Pyparted Interfaces
Last week my co-worker Marek Hruscak, from Red Hat, found an interesting case of mismatch between the two interfaces provided by pyparted. In this article I'm going to give an example, using simplified code and explain what is happening. From pyparted's documentation we learn the following
pyparted is a set of native Python bindings for libparted. libparted is the library portion of the GNU parted project. With pyparted, you can write applications that interact with disk partition tables and filesystems.
The Python bindings are implemented in two layers. Since libparted itself is written in C without any real implementation of objects, a simple 1:1 mapping of externally accessible libparted functions was written. This mapping is provided in the _ped Python module. You can use that module if you want to, but it's really just meant for the larger parted module.
_ped libparted Python bindings, direct 1:1: function mapping parted Native Python code building on _ped, complete with classes, exceptions, and advanced functionality.
The two interfaces are the _ped and parted modules. As a user I expect them
to behave exactly the same but they don't. For example some partition properties
are read-only in libparted and _ped but not in parted. This is the mismatch
I'm talking about.
Consider the following tests (also available on GitHub)
diff --git a/tests/baseclass.py b/tests/baseclass.py
index 4f48b87..30ffc11 100644
--- a/tests/baseclass.py
+++ b/tests/baseclass.py
@@ -168,6 +168,12 @@ class RequiresPartition(RequiresDisk):
self._part = _ped.Partition(disk=self._disk, type=_ped.PARTITION_NORMAL,
self._part = _ped.Partition(disk=self._disk, type=_ped.PARTITION_NORMAL,
start=0, end=100, fs_type=_ped.file_system_type_get("ext2"))
+ geom = parted.Geometry(self.device, start=100, length=100)
+ fs = parted.FileSystem(type='ext2', geometry=geom)
+ self.part = parted.Partition(disk=self.disk, type=parted.PARTITION_NORMAL,
+ geometry=geom, fs=fs)
+
+
# Base class for any test case that requires a hash table of all
# _ped.DiskType objects available
class RequiresDiskTypes(unittest.TestCase):
diff --git a/tests/test__ped_partition.py b/tests/test__ped_partition.py
index 7ef049a..26449b4 100755
--- a/tests/test__ped_partition.py
+++ b/tests/test__ped_partition.py
@@ -62,8 +62,10 @@ class PartitionGetSetTestCase(RequiresPartition):
self.assertRaises(exn, setattr, self._part, "num", 1)
self.assertRaises(exn, setattr, self._part, "fs_type",
_ped.file_system_type_get("fat32"))
- self.assertRaises(exn, setattr, self._part, "geom",
- _ped.Geometry(self._device, 10, 20))
+ with self.assertRaises((AttributeError, TypeError)):
+# setattr(self._part, "geom", _ped.Geometry(self._device, 10, 20))
+ self._part.geom = _ped.Geometry(self._device, 10, 20)
+
self.assertRaises(exn, setattr, self._part, "disk", self._disk)
# Check that values have the right type.
diff --git a/tests/test_parted_partition.py b/tests/test_parted_partition.py
index 0a406a0..8d8d0fd 100755
--- a/tests/test_parted_partition.py
+++ b/tests/test_parted_partition.py
@@ -23,7 +23,7 @@
import parted
import unittest
-from tests.baseclass import RequiresDisk
+from tests.baseclass import RequiresDisk, RequiresPartition
# One class per method, multiple tests per class. For these simple methods,
# that seems like good organization. More complicated methods may require
@@ -34,11 +34,11 @@ class PartitionNewTestCase(unittest.TestCase):
# TODO
self.fail("Unimplemented test case.")
-@unittest.skip("Unimplemented test case.")
-class PartitionGetSetTestCase(unittest.TestCase):
+class PartitionGetSetTestCase(RequiresPartition):
def runTest(self):
- # TODO
- self.fail("Unimplemented test case.")
+ with self.assertRaises((AttributeError, TypeError)):
+ #setattr(self.part, "geometry", parted.Geometry(self.device, start=10, length=20))
+ self.part.geometry = parted.Geometry(self.device, start=10, length=20)
@unittest.skip("Unimplemented test case.")
class PartitionGetFlagTestCase(unittest.TestCase):
The test in test__ped_partition.py works without problems, I've modified it for
visual reference only. This was also the inspiration behind the test in
test_parted_partition.py. However the second test fails with
======================================================================
FAIL: runTest (tests.test_parted_partition.PartitionGetSetTestCase)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/tmp/pyparted/tests/test_parted_partition.py", line 41, in runTest
self.part.geometry = parted.Geometry(self.device, start=10, length=20)
AssertionError: (<type 'exceptions.AttributeError'>, <type 'exceptions.TypeError'>) not raised
----------------------------------------------------------------------
Now it's clear that something isn't quite the same between the two interfaces.
If we look at src/parted/partition.py we see the following snippet
137 fileSystem = property(lambda s: s._fileSystem, lambda s, v: setattr(s, "_fileSystem", v))
138 geometry = property(lambda s: s._geometry, lambda s, v: setattr(s, "_geometry", v))
139 system = property(lambda s: s.__writeOnly("system"), lambda s, v: s.__partition.set_system(v))
140 type = property(lambda s: s.__partition.type, lambda s, v: setattr(s.__partition, "type", v))
The geometry property is indeed read-write but the system property is write-only.
git blame leads us to the interesting
commit 2fc0ee2b, which changes
definitions for quite a few properties and removes the _readOnly method which raises
an exception. Even more interesting is the fact that the Partition.geometry property
hasn't been changed. If you look closer you will notice that the deleted definition and
the new one are exactly the same. Looks like the problem existed even before this change.
Digging down even further we find
commit 7599aa1
which is the very first implementation of the parted module. There you can see the
_readOnly method and some properties like path and disk correctly marked as such
but geometry isn't.
Shortly after this commit the first test was added (4b9de0e) and a bit later the second, empty test class, was added (c85a5e6). This only goes to show that every piece of software needs appropriate QA coverage, which pyparted was kind of lacking (and I'm trying to change that).
The reason this bug went unnoticed for so long
is the limited exposure of pyparted. To my knowledge anaconda, the Fedora installer
is its biggest (if not single) consumer and maybe it uses only the _ped
interface (I didn't check) or it doesn't try to do silly things like setting
a value to a read-only property.
** The lesson from this story is to test all of your interfaces and also make sure they are behaving in exactly the same manner! **
Thanks for reading and happy testing!
There are comments.
Capybara's within() Altering expect(page) Scope
**
When making assertions inside a within block the assertion scope
is limited to the element selected by the within() function, although
it looks like you are asserting on the entire page!
**
scenario 'Pressing Escape closes autocomplete popup' do
within('#new-broadcast') do
find('#broadcast_field').set('Hello ')
start_typing_name('#broadcast_field', '@Bret')
# will fail below
expect(page).to have_selector('.ui-autocomplete')
send_keys('#broadcast_field', :escape)
end
expect(page).to have_no_selector('.ui-autocomplete')
end
The above code failed the first expect() and it took me some time before
I figured it out. Capybara's test suite itself gives you the answer
it "should assert content in the given scope" do
@session.within(:css, "#for_foo") do
expect(@session).not_to have_content('First Name')
end
expect(@session).to have_content('First Name')
end
So know your frameworks and happy testing.
There are comments.
Unix Stickers for Your Laptop
Last month I was asked to review stickers from UnixStickers. In return I would receive some of them. I've made them a counter offer - they send me stickers and I give them to students attending my QA-and-Automation-101 course.

Yesterday I gave away everything I was sent, some of which you can see on the picture above. All stickers were gone in minutes. The ones that were left were the yellow JS ones and the Fedora infinity logo. It turned out most students are not familiar with Fedora but otherwise liked the stickers.
If you haven't come across UnixStickers until now I definitely recommend it. It is a great source to purchase stickers, mugs and T-shirts branded with your favorite open source project(s). In return some of the money is donated back to the community to support their open source work. A great business model in my opinion.
There are comments.
3 Bugs in Grajdanite
Grajdanite is a social app that allows everyone (in Bulgaria) to photograph vehicles in breach of traffic rules or misbehaving drivers, upload them online and ask them to appologize. They also offer some functionality to report offenses to the authorities are are partnering with local municipalities and law enforcement agencies to make the process easier. And of course this is one of my favorite apps as of latest.
Missing Icon in My Profile

The more offenses you report the more points you get. Points lead to ranks (e.g. junior officer, senior officer, etc). The page showing your points and rank is missing an icon. If I had to guess this is the badge which comes with different ranks.
Preloading the Very First Form Value

Once you opt for reporting an offence to the authorities you need to specify the address where the action took place, your name, phone and e-mail address. The app correctly saves your details and pre-loads them later to speed-up data entry. However I typed my e-mail wrong the very first time. Now every time I want to report something the app pre-loads the wrong address. Even after I change it to the correct one, the next time I still see the very first, wrong value.
In code this is probably something like:
# pre-load
form.email = store.get("email", "")
form.show()
# save
if form.firstTime():
store.save("email", form.email)
The fix is to save the form value every time (not expensive operation here) or check if the current value is different from the last time and only then save it.
DST and Time Sync
The last bug is in the app confirmation email. Once an offence is reported the user receives an email with the uploaded photo and the information they have provided. The email includes a timestamp. However the email timestamp is 1 hour off from the actual time. In particular it is 1 hour behind the current time and I think the email server doesn't follow summer time.
The result from this is:
- Report an offense
- Wait 1 minute for the email to be received;
- The email says the offense happened 1 hour ago!
All of these bugs are in version 3.86.3, which is the latest one.
There are comments.
How To Hire Software Testers, Pt. 2
In my previous post I have described the process I follow when interviewing candidates for a QA position. The first question is designed to expose the applicant's way of thinking. My second question is designed to examine their technical understanding and to a lesser extent their way of thinking.

How do You Test a Sudoku Solving Function
You have implementation of a sudoku solver function with the following pseudocode:
func Sudoku(Array[2]) {
...
return Array[2]
}
- The function solves a sudoku puzzle;
- Input parameter is a two-dimensional array with the known numbers (from 1 to 9) in the Sudoku grid;
- The output is a two-dimensional array with the numbers from the solved puzzle.
You have 10 minutes to write down a list of all test cases you can think of!
Behind The Scenes
One set of possible tests is to examine the input and figure out if the function has been passed valid data. In the real-world programs interact with each other, they are not alone. Sometimes it happens that a valid output from one program isn't a valid input for the next one. Also we have malicious users who will try to break the program.
If a person manages to test for this case then I know they have a bit more clue about how software is used in the real-world. This also touches a bit on white-box testing, where the tester has full info about the software under test. In this example the implementation is intentionally left blank.
OTOH I've seen answers where the applicant blindly assumes that the input is 1-9, because the spec says so, and excludes the entire input testing from their scope. I classify this answer as immediate failure, because a tester should never assume anything and test to verify their initial conditions are indeed as stated in the documentation.
Another set of possible tests is to verify the correct work of the function. That is to verify the proposed Sudoku solution is indeed following the rules of the game. This is what we usually refer to black-box testing. The tester doesn't know how the SUT works internally, they only know the input data and the expected output.
If a person fails to describe at least one such test case they have essentially failed the question. What is the point of a SUT which doesn't crash (suppose that all previous tests passed) but doesn't produce the desired correct result ?
Then there are test cases related to the environment in which this Sudoku solver function operates. This is where I examine the creativity of the person, their familiarity with other platforms and to some extent their thinking out of the box. Is the Sudoku solver iterative or recursive ? What if we're on an embedded system and recursion is too heavy for it ? How much power does the function require, how fast it works, etc.
A person that provides at least one answer in this category has bonus points over the others who didn't. IMO it is very important for a tester to have experience with various platforms and environments because this helps them see edge cases which others will not be able to see. I also consider a strong plus if the person shows they can operate outside their comfort zone.
If we have time I may ask the applicant to write the tests using a programming language they know. This is to verify their coding and automation skills.
OTOH having the tests as code will show me how much the person knows about testing
vs. coding. I've seen solutions where people write a for loop, looping over all
numbers from 1 to 100 and testing if they are a valid input to Sudoku().
Obviously this is pointless and they failed the test.
Last but not least, the question asks for testing a particular Sudoku solver implementation. I expect the answers to be designed around the given function. However I've seen answers designed around a Sudoku solver website or described as intermediate states in an interactive Sudoku game (e.g. wrong answers shown in red). I consider these invalid because the question is to test a particular given function, not anything Sudoku related. If you do this in real-life that means you are not testing the SUT directly but maybe touching it indirectly (at best). This is not what a QA job is about.
What Are The Correct Answers
Here are some of the possible tests.
- Test with single dimensional input array - we expect an error;
- Test with 3 dimensional input array - we expect an error;
- Then proceed testing with 2 dimensional array;
- Test with number less than 1 (usually 0) - expect error;
- Test with number greater than 9 (usually 10) - expect error;
- Test how the function handles non-numerical data - chars & symbols (essentially the same thing for our function);
- Test with strings which actually represent a number, e.g. "1";
- Test with floating point numbers, e.g. 1.0, 2.0, 3.0 - may or may not work depending on how the code is written;
- If floating point numbers are accepted, then test with a different locale. Is "1.0" the same as "1,0";
- Test with
null,nil,None(whatever the language supports) - this should be a valid value for unknown numbers and not cause a crash; - Test if the function validates that the provided input follows the Sudoku rules by passing it duplicate numbers in one row, column or square. It should produce an error;
- Test if the input data contains the minimum number of givens, 17 for a general Sudoku, so that a solution can be found. Otherwise the function may go into an endless loop;
- Verify the proposed solution conforms to Sudoku rules;
- Test with a fully solved puzzle as input - output should be exactly the same;
- If on mobile, measure battery consumption for 1 minute of operation. I've seen a game which uses 1% battery power for 1 minute of game play;
- Test for buffer overflows;
- Test for speed of execution (performance);
- Test performance on single and multiple (core) CPUs - depending on the language and how the function is written this may produce a difference or not;
I'm sure I'm missing something so please use the comments below to tell me your suggestions.
Thanks for reading and happy testing!
There are comments.
How To Hire Software Testers, Pt. 1
Many people have asked me how do I make sure a person who applies for a QA/software tester position is a good fit ? On the opposite side people have asked online how do they give correct answers on test related questions at job interviews. I have two general questions to help me decide if a person knows about testing and if they are a good fit for the team or not.

How do You Test a Login Form
You are given the login form above and the following constraints:
- Log in is possible with username and password or through the social networks;
- After successful registration an email with the following content is sent to the user:
Helo and welcome to atodorov.org! Click _here_ to confirm your emeil address.
You have 10 minutes to write down a list of all test cases you can think of!
Behind The Scenes
The question looks trivial but isn't as easy to answer as you may think. If you haven't spent the last 20 years of your life in a cave, chances are that you will give technically correct answers but this is not the only thing I'm looking for.
The question is designed to simulate a real-world scenario, where the QA person is given a piece of software, or requirements document and tasked with creating a test plan for it. The question is intentionally vague because that's how real-world works, most often testers don't have all the requirements and specifications available beforehand.
The time constrain, especially when the interview is performed in person, simulates work under pressure - get the job done as soon as possible.
While I review the answers I'm trying to figure out how does the person think, not how much about technology they know. I'm trying to figure out what are their strong areas and where they need to improve. IMO being able to think as a tester and having attention to details, being able to easily spot corner cases and look at the problem from different angles is much more important than technical knowledge in a particular domain.
As long as a person is suited to think like a tester they can learn to apply their critical thinking to any software under test and use various testing techniques to discover or safeguard against problems.
-
A person that answers quickly and intuitively is better than a person who takes a long time to figure out what to test. I can see they are active thinkers and can work without micro-management and hand-holding.
-
A person that goes on and on describing different test cases is better than one who limits themselves to the most obvious cases. I can see they have an exploratory passion, which is the key to finding many bugs and making the software better;
-
A person that goes to explore the system in breadth is better than one who keeps banging on the same test case with more and more variations. I can see they are noticing the various aspects of the software (e.g. social login, email confirmation, etc) but also to some extent, not investing all of their resources (the remaining time to answer) into a single direction. Also in real-world testing, testing the crap out of something is useful up to a point. Afterwards we don't really see any significant value from additional testing efforts.
-
A person that is quick to figure out one or two corner cases is better than a person who can't. This tells me they are thinking about what goes on under the hood and trying to predict unpredictable behavior - for example what happens if you try to register with already registered username or email?
-
A person that asks questions in order to minimize uncertainty and vagueness is better than the one who doesn't. In real-world if the tester doesn't know something they have to ask. Quite often even developers and product managers don't know the answer. Then how are we developing software if we don't know what it is supposed to do ?
-
If given more time (writing interview), a person that organizes their answers into steps (1, 2, 3) is a bit better than one who simply throws at you random answers without context. Similar thought applies to people who write down their test pre-conditions before writing down scenarios. From this I can see that the person is well organized and will have no trouble writing detailed test cases, with pre-conditions, steps to execute and expected results. This is what QAs do. Also we have the, sometimes tedious, task of organizing all test results into a test case management system (aka test book) for further reference.
-
The question intentionally includes some mistakes. In this example 2 spelling errors in the email text. Whoever manages to spot them and tell me about it is better than others who don't spot the errors or assume that's how it is. QAs job is to always question everything and never blindly trust that the state of the system is the way it is. Also simple errors like typos can be embarrassing or generate unnecessary support calls.
-
Bravo if you tested not only the outgoing email but also social login. This shows attention to details, not to mention social is 1/3rd of our example system. It also shows that QA's job doesn't end with testing the core, perceived functionality of the system. QA tests everything, even interactions with external systems if that is necessary.
What Are The Correct Answers
I will document some of the possible answers as I recall them from memory. I will update the list with other interesting answers given by students who applied to my QA and Automation 101 course, answering this very same question.
- Test if users can register using valid username, email and password;
- Test if SUT gives an error message when email or password (or username) format doesn't follow a particular format (e.g. no special symbols);
- After registration, test that the user can login successfully;
- Depending on requirements test if the user can login before they have confirmed their email address;
- Test that upon registration a confirmation email is actually sent;
- Spell-check the email text;
- Test if the click here piece of text is a hyperlink;
- Verify that when clicked, the hyperlink successfully confirmed email/activates the account (depending on what confirmed/activated means per requirements);
- Test what happens if the link is clicked a second time;
- Test what happens if the link is clicked after 24 or 48 hrs;
- Test that the social network icons, actually link to the desired SN and not someplace else;
- Test if new user accounts can be created via all specified social networks;
- Test what happens if there is an existing user, who registered with a password and they (or somebody else) tries to register via social with an account that has the same email address, aka account hijacking;
- Same as previous test but try to register a new user, using email address that was previously used with social login;
- Test what happens if users forget their password - intentionally we don't have the '[] Forgot my password' checkbox. This is both usability feature and missing requirements;
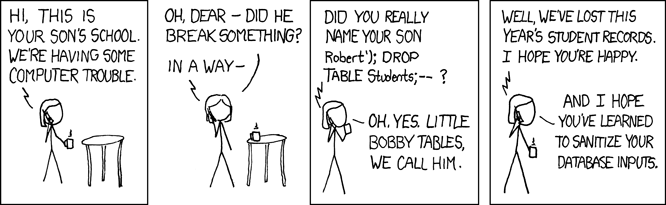
- Test for simple SQL injections like Bobby Tables. btw I was given this image as an answer which scored high on the geek-o-meter;
- Test for XSS - Tweetdeck didn't;
- Test if non-activated/non-confirmed usernames expire after some time and can be used again;
- Test of fields tab order - something I haven't done in 15 or more years but still valid and I've seen sites getting it wrong quite often;
- When trying to login test what happens when username/password is wrong or empty;
- Test if email is required for login - this isn't clear from the requirements so it is a valid answer. Better answer is to clarify that;
- Test if username/email or password is case sensitive. Valid test and indeed I recently saw a problem where upon registration users entered their emails using some capital letters but they were lower-cased before saving to the DB. Later this broke a piece of code which forgot to apply the lowercase on the input data. The code was handling account reactivation;
- Test if the password field shows the actual password or not. I haven't seen this in person but I'm certain there is some site which maybe used CSS and nice images instead of the default ugly password field and that didn't work on all browsers;
- Test if you can copy&paste the masked password, probably trying to steal somebody else's password. Last time I saw this was on early Windows 95 with the modem connection dialog. Very briefly it allowed you to copy the text from the field and paste it into Notepad to reveal the actual password;
- If we're on mobile (intentionally not specified) test for buffer overflows; Actually test that everywhere and see what happens;
- Test if the social network buttons use the same action verb. In the example we have Log in, Connect and Sign in. This is sort of usability testing and helping have a unified look and feel of the product;
- Test which of the Log in and Sign up tabs is active at the moment. The example is intentionally left to look like a wireframe but it is important for the user to easily tell where they are. Otherwise they'll call support or even worse, simply give up on us;
- Test if all static files (images) will load if they are deployed onto CDN. Not surprisingly I've seen this bug;
- In case we have a "[] Remember me" checkbox, test if it actually remembers the user credentials. Yesterday I saw this same functionality not working on a specialized desktop app in the corner case where you supply a different connection endpoint (server) instead of the ones already provided. The user defined value is accepted but not saved automatically;
- Test if the "Remember me" functionality actually saves your last credentials or only the first ones you provided. There is a similar bug in Grajdanite, where once you enter a wrong email, it is remembered and every time the form is pre-filled with the previous value (which is wrong). I'm yet to report it though;
- Cross-browser testing - hmm, login and registration should work on all browsers you say. It's not browser dependent, is it? Well yeah, login isn't browser dependent unless we did something stupid like pre-handling the form submit via non-cross-platform JavaScript or even accidentally doing so;
- Test with Unicode characters, especially non Latin ones. It's been many years since we had Unicode but quite a few apps haven't learned how to deal with Unicode text properly.
{kind=link}
I'm certain there are more answers and I will update the list as I figure them out. You can always post in the comments and tell me something I've missed.
How to Pass The Job Interview
This is a question I often see on Quora. I have a job interview tomorrow. How do I test a login form (or whatever) ?
If this section is what you're after I suspect you are a junior or wanna-be software tester. As you've seen the interviewer isn't really interested in what you know already, at least not as much. We're interested in getting to know how you think in the course of 30-60 minutes.
If you ever find yourself being asked a similar question just start thinking and answering and don't stop. Vocalize your thoughts, even if you don't know what will happen when testing a certain condition. Then keep going on and on. Look at the problem from all angles, explain how you'd test various aspects and features of the SUT. Then move on to the next bit. Always think about what you may have forgotten and revisit your answers - this is what real QAs do - learn from mistakes. Ask questions, don't ever assume anything. If something is unclear ask to be clarified. For example I've seen a person who doesn't use social networks and didn't know how social login/registration worked. They did good by asking me to describe how that works.
Your goal is to make the interviewer ask you to stop answering. Then tell them a few more answers.
However beware of cheating. You may cheat a little bit by saying you will test this and that or design scenarios you have no clue about. Maybe you read them in my blog or elsewhere. If the interviewer knows their job (which they should) they will instantly ask you another question to verify what you say. Don't forget the interviewer is probably an experienced tester and validating assumptions is what they do every day.
For example, if you told me something about security testing or SQL injection or XSS I will ask you to explain that in more details. If you forgot to mention, one of them, say XSS but only heard about SQL injection I will ask you about the other one. This will immediately tell me if you have a clue what you are talking about.
Feel free to send me suggestions and answers in the comments below. You can find the second part of this post at How do you test a Sudoku solving function.
Thanks for reading and happy testing!
There are comments.
Time Calculation bug in BlackBerry Z10

I thought BlackBerry 10 is dead but apparently they still provide updates and introduce new bugs :). This one happened a few days ago with Software Release 10.3.2.2474. As you can see the time calculations are totally wrong!
The current time is 12:45, March 28th. The last call is reported as 5 minutes ago but its time stamp is 3 and a half hours ago!
The second call is reported as 11 minutes ago but in reality it is 3 days ago. I'm not sure about the time stamp but that is probably wrong as well.
The reason for this IMO is their design to have a fixed start of the epoch for every OS release - probably the build time of the release. When the OS is fully booted and connected to network it synchronizes with time servers and updates the local time. This of course fails in case of no WiFi, no cellular data or if automatic time synchronization is turned off!
The result is that every object (calls, images, etc) which has a time stamp attached to it gets an incorrect value. Maybe some of these are recalculated back to the current time, once it is synchronized, and others probably not. Otherwise I'd expect all calls to be reported way back in time!
For more information about time related bugs checkout Tom Scott's Why 1/1/1970 Bricks Your iPhone video and read my article Floating-point precision error with Ruby.
There are comments.
Beware of Double Stubs in RSpec
I've been re-factoring some RSpec tests and encountered a method which has been stubbed-out 2 times in a row. This of course led to problems when I tried to delete some of the code, which I deemed unnecessary. Using Treehouse's burger example I've recreated my use-case. Comments are in the code below:
class Burger
attr_reader :options
def initialize(options={})
@options = options
end
def apply_ketchup(number=0)
@ketchup = @options[:ketchup]
# the number is passed from the tests below to make it easier to
# monitor execution of this method.
printf "Ketchup applied %d times\n", number
end
def apply_mayo_and_ketchup(number=0)
@options[:mayo] = true
apply_ketchup(number)
end
def has_ketchup_on_it?
@ketchup
end
end
describe Burger do
describe "#apply_mayo_and_ketchup" do
context "with ketchup and single stubs" do
let(:burger) { Burger.new(:ketchup => true) }
it "1: sets the mayo flag to true, ketchup is nil" do
# this line stubs-out the apply_ketchup method
# and @ketchup will remain nil b/c the original
# method is not executed at all
expect(burger).to receive(:apply_ketchup)
burger.apply_mayo_and_ketchup(1)
expect(burger.options[:mayo]).to eq(true)
expect(burger.has_ketchup_on_it?).to be(nil)
end
it "2: sets the mayo and ketchup flags to true" do
# this line stubs-out the apply_ketchup method
# but in the end calls the non-stubbed out version as well
# so that has_ketchup_on_it? will return true !
expect(burger).to receive(:apply_ketchup).and_call_original
burger.apply_mayo_and_ketchup(2)
expect(burger.options[:mayo]).to eq(true)
expect(burger.has_ketchup_on_it?).to eq(true)
end
end
context "with ketchup and double stubs" do
let(:burger) { Burger.new(:ketchup => true) }
before {
# this line creates a stub for the apply_ketchup method
allow(burger).to receive(:apply_ketchup)
}
it "3: sets the mayo flag to true, ketchup is nil" do
# this line creates a second stub for the fake apply_ketchup method
# @ketchup will remain nil b/c the original method which sets its value
# isn't actually executed. we may as well comment out this line and
# this will not affect the test at all
expect(burger).to receive(:apply_ketchup)
burger.apply_mayo_and_ketchup(3)
expect(burger.options[:mayo]).to eq(true)
expect(burger.has_ketchup_on_it?).to be(nil)
end
it "4: sets the mayo and ketchup flags to true" do
# this line creates a second stub for the fake apply_ketchup method.
# .and_call_original will traverse up the stubs and call the original
# method. If we don't want to assert that the method has been called
# or we don't care about its parameters, but only the end result
# that system state has been changed then this line is redundant!
# Don't stub & call the original, just call the original method, right?
# Commenting out this line will cause a failure due to the first stub
# in before() above. The first stub will execute and @ketchup will remain
# nil! To set things straight also comment out the allow() line in
# before()!
expect(burger).to receive(:apply_ketchup).and_call_original
burger.apply_mayo_and_ketchup(4)
expect(burger.options[:mayo]).to eq(true)
expect(burger.has_ketchup_on_it?).to eq(true)
end
end
end
end
When I see a .and_call_original method
after a stub I immediately delete it because in most of the cases this isn't
necessary. Why stub out something just to call it again later ? See my comments
above. Also the expect to receive && do action
sequence is a bit counter intuitive. I prefer the do action & assert results
sequence instead.
The problem here comes from the fact that RSpec has very flexible syntax for creating stubs which makes it very easy to abuse them, especially when you have no idea what you're doing. If you write tests with RSpec please make a note of this and try to avoid this mistake.
If you'd like to learn more about stubs see Bad Stub Design in DNF.
There are comments.
Hello World QA Challenge
Recently I've been asked on Quora "Do simple programs like hello world have any bugs" ? In particular if the computer hardware and OS are healthy, will there be any bugs in a simple hello-world program?
I'm challenging you to tell me what kinds of bugs have you seen which would easily apply to a very simple program! Below are some I was able to think about.
Localization
Once we add a requirement to our system to work in environment which supports multiple languages and input methods, not supporting them immediately becomes a bug, although the SUT still functions correctly. For example, if using a French locale I would expect the program to print "Bonjour le monde". Same for German, Spanish, Italian, etc. It even becomes trickier with languages using non-latin script like Bulgarian and Japanese for example. Depending on your environment you may not be able to display non-latin script at all. See also How do you test fonts!
Packaging and distribution
This is an entire class of problems not directly related to the SUT but to the way it is packaged and distributed to its target customers. For a Linux system it makes sense to have an RPM or DEB packages. Dependency resolution and proper installation and upgrade for these packages need to be tested and ensured.
A famous example of a high impact packaging bug is
Django #19858. During an urgent
security release it was discovered that the source package was shipping byte-compiled
*.pyc files made with a newer version of Python (2.7). Even worse there were
byte-compiled files without the corresponding source files.
Being a security release everyone
rushed to upgrade immediately. Everyone who had Python 2.6 saw their website
produce ImportError: Bad magic number and crash immediately after the upgrade!
NOTE: byte-compiled files between different versions of Python are incompatible!
Another one is django-facebook #262 in which version 4.3.0 suddenly grew from 200KiB to 23MiB in size, shipping a ton of extra JPEG images.
Portability
There are so many different portability issues which may affect an otherwise working program. You only need to add a requirement to build/execute on another OS or CPU architecture - for example aarch64 (64-bit ARM). This resulted in hundreds of bugs reported by Dennis Gilmore, for example RHBZ #926850 which is also related to packaging and the build chain.
Then we have possibility for big endian vs. little endian issues especially if we run on Power 8 CPU which supports both modes.
Another one could be 16bit vs. 32bit vs 64bit memory addressing. For example on platforms like IBM mainframe (s390) they reserved the most significant bit to easily support applications expecting 24-bit addressing, as well as to sidestep a problem with extending two instructions to handle 32-bit unsigned addresses, which made the address space 31-bits!
Performance
Not all processors are created equal! Both Intel (x86_64), ARM and PowerPC have different instruction sets and numbers of registers. Depending on what sort of calculations you perform one of the architectures may be more suitable than the other.
Typos
It not uncommon to mistype even common words like "hello" and "world" and I've rarely seen QAs and developers running spell checkers on all of their source strings. We do this for documentation and occasionally for man pages but for the actual program output or widget labels - almost never.
Challenge
I find the original question very interesting and a good metal exercise for IT professionals. I will be going through Bugzilla to find examples which illustrate the above points and even more possible problems with a program as simple as hello world and will update this blog accordingly!
Tell me what kinds of bugs have you seen which would easily apply to a very simple program! It's best if you can post links to public bugs and/or detailed explanation. Thanks!
There are comments.
QA Switch from Waterfall to BDD
For the last two weeks I've been experimenting with Behavior-Driven Development (BDD) in order to find out what it takes for the Quality Assurance department to switch from using the Waterfall method to BDD. Here are my initial observations and thoughts for further investigation.
Background
Developing an entire Linux distribution (or any large product for that matter) is a very complicated task. Traditionally QA has been involved in writing the test plans for the proposed technology updates, then execute and maintain them during the entire product life-cycle reporting and verifying tons of bugs along the way. From the point of view of the entire product the process is very close to the traditional waterfall development method. I will be using the term waterfall to describe the old way of doing things and BDD the new one. In particular I'm referring to the process of analyzing the proposed feature set for the next major version of the product (e.g. Fedora) and designing the necessary test plans documents and test cases.
To get an idea about where does QA join the process see the Fedora 24 Change set. When the planning phase starts we are given these "feature pages" from which QA needs to distill test plans and test cases. The challenges with the waterfall model are that QA joins the planning process rather late and there is not enough time to iron out all the necessary details. Add to this the fact that feature pages are often incomplete and vaguely described and sometimes looking for the right answers is the hardest part of the job.
QA and BDD
Right now I'm focusing on using the Gherkin Given-When-Then language to prepare feature descriptions and test scenarios from the above feature pages. You can follow my work on GitHub and I will be using them as examples below. Also see examples from my co-workers 1, 2.
With this experiment I want to verify how hard/easy it is for QA to write test cases using BDD style documents and how is that different from the traditional method. Since I don't have any experience (nor bias) towards BDD I'm documenting my notes and items of interest.
Getting Started
It took me about 2 hours to get started. The essence of Gherkin is the Action & Response mechanism. Given the system under test (SUT) is in a known state and when an action is taken then we expect something to happen in response to the action. This syntax made me think from the point of view of the user. This way it was very easy to identify different user roles and actions which will be attempted with the SUT. This also made my test scenarios more explicit compared to what is described in the wiki pages. IMO being explicit when designing tests is a good thing. I like it that way.
OTOH the same explicitness can be achieved with the waterfall method as well. The trouble is that this is often overlooked because we're not in the mindset to analyze the various user roles and scenarios. When writing test cases with waterfall the mindset is more focused on the technical features, e.g. how the SUT exactly works and we end up missing important interactions between the user and the system. At least I can recall a few times that I've made that mistake.
Tagging the scenarios is a good way of indicating which scenario covers which roles. Depending on the tools you use it should be possible to execute test scenarios for different roles (tags). In waterfall we need to have a separate test plan for each user role, possibly duplicating some of the test cases across test plans. A bit redundant but more importantly easier to forget the bigger picture.
Big, Small & Undefined
BDD originates from TDD which in turn relies heavily on unit testing and automation. This makes it very easy to use BDD test development (and even automate) for self contained changes, especially ones which affect only a single component (e.g. a single program). From the Fedora 24 changes such are for example the systemd and system-python split.
I happen to work in a team where we deal with large changes, which affect multiple components and infrastructure. Both the Pungi Refactor and Layered Docker Image Build Service for which I've written BDD style test scenarios are of this nature. This leads to the following issues:
- QA doesn't always have the entire infrastructure stack in a staging environment for testing so we need to test on the live infra;
- QA doesn't always have the necessary access permissions to execute the tests and in some cases never will. For example it is very unlikely that QA will be able to build a test release and push that for syncing to the mirrors infrastructure to verify that there are no files left behind;
- Not being able to test independently means QA has to wait for something to happen then verify the results (e.g. rel-eng builds new Docker images and pushes them live). When something breaks this testing is often too late.
Complex changes are often not described into detail. As they affect multiple infrastructure layers and components sometimes it is not known what the required changes need to be. That's why we implement them in stages and have contingency plans. However this makes it harder for QA to write the tests. Btw this is the same regardless of which development method is used. The good thing is that by forcing you to think from the POV of the user and in terms of action & response BDD helps identify these missing bits faster.
For example, with Pungi (Fedora distro build tool), the feature pages says that the produced directory structure will be different from previous releases but it doesn't say what is going to be different so we can't really test that. I know from experience that this may break tools which rely on this structure like virt-manager and anaconda and have added simple sanity tests for them.
In the Docker feature page we have functional requirement for automatic image rebuilds if one of the underlying components (e.g. RPM package) changes. This is not described in details and so is the test scenario. I can easily write a separate BDD feature document for this functionality alone.
With the waterfall model when a feature isn't well defined QA often waits for the devel team to implement the basic features and then writes test cases based on the existing behavior. This is only good for regression testing the next version but it can't show you something that is missing because we're never going to look for it. BDD makes it easier to spot when we need better definitions of scope and roles, even better functional requirements.
Automation and Integration
Having a small SUT is nice. For example we can easily write a test script to install, upgrade and query RPM packages and verify the systemd package split. We can easily prepare a test system and execute the scripts to verify the expected results.
OTOH complex features are hard to integrate with BDD automation tools. For the Docker Image Build Service the straight forward script would be to start building a new image, then change an underlying component and see if it gets rebuilt, then ensure all the content comes from the existing RPM repos, then push the image to the Docker registry and verify it can be used by the user, etc, etc. All of these steps take a non-trivial amount of time. Sometimes hours. You can also execute them in parallel to save time but how do you sync back the results ?
My preference for the moment is to kick-off individual test suites for a particular BDD scenario and then aggregate the results back. This also has a side benefit - for complex changes we can have layered BDD feature documents, each one referencing another feature document. Repeat this over and over until we get down to purely technical scenarios which can be tested easily. Once the result are in go back the chain and fill-in the rest. This way we can traverse all testing activities from the unit testing level up to the infrastructure level.
I actually like the back & forth traversing idea very much. I've always wanted to know how does each individual testing effort relate to the general product development strategy and in which areas the product is doing well or not. You can construct the same chain of events with waterfall as well. IMO BDD just makes it a bit more easier to think about it.
Another problem I faced is how do I mark the scenarios as out of scope for the current release ? I can tag them or split them into separate files or maybe something else? I don't know which one is the best practice. In waterfall I'll just disable the test cases or move them into a separate test plan.
TODO
I will be writing more BDD test definitions in the upcoming 2 weeks to get more experience with them. I still don't have a clear idea how to approach BDD test writing when given a particular feature to work on. So far I've used the functional requirements and items of concern (when present), in the feature pages, as a starting point for my BDD test scenarios.
I also want to get more feedback from the development teams and product management folks.
Summary
BDD style test writing puts the tester into a mind set where it is easier to see the big picture by visualizing different user roles and scenarios. It makes it easier to define explicit test cases and highlights missing details. It is easier for QA to join early in the planning process by defining roles and thinking about all the possible interactions with the SUT. This is the biggest benefit for me!
Self-contained changes are easier to describe and test automatically.
Bigger and complex features are harder to describe and even harder to automate in one piece. Divide and conqueror is our best friend here!
There are comments.
Floating-point precision error with Ruby
One of my tests was faiing and it turned out this was caused by a floating-point precision error. The functionality in question was a "Load more" button with pagination which loads records from the database and the front-end displays them.
Ruby and JavaScript were passing around a parameter
which was only used as part of the SQL queries.
Now the problem is that JavaScript doesn't have a Time class and the parameter
was passed as string, then converted back to Time in Ruby. The problem
comes from the intermediate conversion to float which was used.
Here's a little code snippet to demonstrate the problem:
irb(main):068:0* now = Time.now
=> 2016-03-08 10:54:26 +0200
irb(main):069:0>
irb(main):070:0* Time.at(now) == now
=> true
irb(main):071:0>
irb(main):072:0* Time.at(now.to_f) == now
=> false
irb(main):073:0>
irb(main):074:0* now.to_f
=> 1457427266.7206197
irb(main):075:0>
irb(main):076:0* now.strftime('%Y-%m-%d %H:%M:%S.%9N')
=> "2016-03-08 10:54:26.720619705"
irb(main):077:0>
irb(main):079:0* Time.at(now.to_f).strftime('%Y-%m-%d %H:%M:%S.%9N')
=> "2016-03-08 10:54:26.720619678"
irb(main):080:0>
As you can see the conversion to float and back to Time is off by a few nano-seconds and the database either didn't return any records or was returning the same set of records. This isn't something you can usually see in production, right ? Unless you have huge traffic and happen to have records created exactly at the same moment.
The solution is to simply send Time.now.strftime to the JavaScript and then
use Time.parse to reconstruct the value.
irb(main):077:0>
irb(main):001:0> require 'time'
=> true
irb(main):002:0> Time.parse(now.strftime('%Y-%m-%d %H:%M:%S.%9N')).strftime('%Y-%m-%d %H:%M:%S.%9N')
=> "2016-03-08 10:54:26.720619705"
irb(main):003:0>
If you'd like to read more about floating point arithmetics please see http://floating-point-gui.de.
There are comments.
Puppet for Complete Beginners
I guess everyone knows what Puppet is but probably not everyone knows how to write Puppet modules. This article outlines what I've learned while adding a new module to an existing Puppet configuration without having any previous knowledge beforehand and not reading the official documentation (which I should have done).
Existing setup
The existing setup is a single git repository, which holds all of the Puppet
configuration for all hosts and environments. The main directory inside the
repo is puppet/modules. I wanted to add a few Python scripts which automate
tasks inside YouTrack.
What to do next
First step in understanding Puppet was to figure out what do I need to do ?
- Have my scripts inside the repository;
- Provide configuration file for credentials;
- Configure cron jobs;
- Install all of this on one of the existing systems.
My directory layout looks like this
./puppet/modules/youtrack/
./files/archive
./manifests/init.pp
./templates/youtrack.conf.erb
files/ is where all the scripts go. They can be accessed from here later on.
manifests/init.pp is the definition of this module - what gets installed where
and so on. templates/ is where templates go. These are usually config files
which use a placeholder for their values.
My files/archive is a simple executable Python script, which queries YouTrack
for old issues and archives them. It looks for a youtrack.conf file at a
pre-defined location (the location on the host system) or at environment variables
for testing purposes.
templates/youtrack.conf.erb looks like this
[main]
url = <%= scope.lookupvar('common::vars::youtrack_url') %>
user = <%= scope.lookupvar('common::vars::youtrack_user') %>
pass = <%= scope.lookupvar('common::vars::youtrack_pass') %>
manifests/init.pp looks like this
class youtrack {
$youtrack_files =
'/opt/devops/puppet/modules/youtrack/files'
file { '/opt/youtrack.conf':
content => template('youtrack/youtrack.conf.erb'),
}
cron { 'Archive issues older than 2 weeks':
ensure => present,
command => "cd ${youtrack_files} && ${youtrack_files}/archive",
environment => [ 'MAILTO=devops@example.com' ],
user => 'root',
minute => 0,
hour => 8,
}
}
Once Puppet applies this configuration on the host system it will
- Install the configuration template under
/opt/youtrack.confreplacing the placeholder variables with actual values. Notice the argument totemplate()- it's of the form module_name/file_name; - Add a cron job entry for my Python script.
NOTE: The host system is the Puppet master so I don't really need to install my Python scripts into another location. I could if I wanted to but this isn't necessary. Cron is executing the script from inside the git checkout.
Bundle it all together
Our module is done. Now we need to instruct Puppet that we want to use it.
I have a puppet/modules/role/manifests/pmaster.pp which defines what modules
get used on the Puppet master machine. pmaster matches the hostname of the
system (that's how it's been configured to work). The module looks like this
class role::pmaster {
include youtrack
...
}
There is also a puppet/modules/common/manifests/vars-static.pp file which
defines all the variables used in the templates. Simply add the necessary ones
at the bottom:
@@ -197,4 +197,9 @@
+
+ # YouTrack automation
+ $youtrack_url = 'http://example.com'
+ $youtrack_user = 'changeMe'
+ $youtrack_pass = 'changeMe'
}
NOTE: in reality this file is just a placeholder. The real values are not
stored in git but are configured manually on systems which need them. On the
Puppet master there are separate XXX-vars.pp files for different environments
like devel, staging and production.
There are comments.
Ruby & Time-based Testing
Publishing this mostly for self reference. Here are two blog posts on the topic of testing time dependent code in Ruby applications:
Synchronized Times In Ruby & JavaScript Acceptance Tests Using Capybara, Timecop & Sinon.JS
Move Over Timecop…Hello ActiveSupport::Testing::TimeHelpers
I haven't seen a module similar to timecop in Python, but frankly I've never needed one either.
There are comments.
Bulgaria Web Summit 2016 Report & Videos

Hello everyone, this year I've been moderator at Bulgaria Web Summit again. Here is a quick report of the even as seen from the room I was at.
The morning sessions were dominated by database topics including MariaDB, RocksDB and MammothDB. The MariaDB talk was particularly strong while the rest were with average attendance.
In the afternoon we switched to DevOps and Docker and the room exploded. There were people sitting on the ground and standing around the walls. There was not enough oxygen for everyone in the room.
I have recorded all of the talks from this room. Most are in English. You can watch them at my YouTube channel and I hope to see you next year in Sofia.
There are comments.
Page 4 / 16