Bug in Python URLGrabber/cURL on Fedora and Amazon Linux
Accidentally I have discovered a bug for Python's URLGrabber module which has to do with change in behavior in libcurl.
>>> from urlgrabber.grabber import URLGrabber
>>> g = URLGrabber(reget=None)
>>> g.urlgrab('https://s3.amazonaws.com/production.s3.rubygems.org/gems/columnize-0.3.6.gem', '/tmp/columnize.gem')
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "/home/celeryd/.virtualenvs/difio/lib/python2.6/site-packages/urlgrabber/grabber.py", line 976, in urlgrab
return self._retry(opts, retryfunc, url, filename)
File "/home/celeryd/.virtualenvs/difio/lib/python2.6/site-packages/urlgrabber/grabber.py", line 880, in _retry
r = apply(func, (opts,) + args, {})
File "/home/celeryd/.virtualenvs/difio/lib/python2.6/site-packages/urlgrabber/grabber.py", line 962, in retryfunc
fo = PyCurlFileObject(url, filename, opts)
File "/home/celeryd/.virtualenvs/difio/lib/python2.6/site-packages/urlgrabber/grabber.py", line 1056, in __init__
self._do_open()
File "/home/celeryd/.virtualenvs/difio/lib/python2.6/site-packages/urlgrabber/grabber.py", line 1307, in _do_open
self._set_opts()
File "/home/celeryd/.virtualenvs/difio/lib/python2.6/site-packages/urlgrabber/grabber.py", line 1161, in _set_opts
self.curl_obj.setopt(pycurl.SSL_VERIFYHOST, opts.ssl_verify_host)
error: (43, '')
>>>
The code above works fine with curl-7.27 or older while it breaks with curl-7.29 and newer. As explained by Zdenek Pavlas the reason is an internal change in libcurl which doesn't accept a value of 1 anymore!
The bug is reproducible with a newer libcurl version and a vanilla urlgrabber==3.9.1 from PyPI (e.g. inside a virtualenv). The latest python-urlgrabber RPM packages in both Fedora and Amazon Linux already have the fix.
I have tested the patch proposed by Zdenek and it works for me. I still have no idea why there aren't any updates released on PyPI though!
There are comments.
Open Source Quality Assurance Infrastructure for Fedora QA

In the last few weeks I've been working together with Tim Flink and Kamil Paral from the Fedora QA team on bringing some installation testing expertise to Fedora and establishing an open source test lab to perform automated testing in. The infrastructure is already in relatively usable condition so I've decided to share this information with the community.
Beaker is Running Our Test Lab
Beaker is the software suite that powers the test lab infrastructure. It is quite complex, with many components and sometimes not very straight-forward to set up. Tim has been working on that with me giving it a try and reporting issues as they have been discovered and fixed.
In the process of working on this I've managed to create couple of patches against Beaker and friends. They are still pending release in a future version because of more urgent bug fixes which need to released first.
SNAKE is The Kickstart Template Server
SNAKE is a client/server Python framework used to support Anaconda installations. It supports plain text ks.cfg files, IIRC those were static templates, no variable substitution.
The other possibility is Python templates based on Pykickstart:
from pykickstart.constants import KS_SCRIPT_POST
from pykickstart.parser import Script
from installdefaults import InstallKs
def ks(**context):
'''Anaconda autopart'''
ks=InstallKs()
ks.packages.add(['@base'])
ks.clearpart(initAll=True)
ks.autopart(autopart=True)
script = '''
cp /tmp/ks.cfg /mnt/sysimage/root/ks.cfg || \
cp /run/install/ks.cfg /mnt/sysimage/root/ks.cfg
'''
post = Script(script, type=KS_SCRIPT_POST, inChroot=False)
ks.scripts.append(post)
return ks
At the moment SNAKE is essentially abandoned but feature complete. I'm thinking about adopting the project just in case we need to make some fixes. Will let you know more about this when it happens.
Open Source Test Suite
I have been working on opening up several test cases for what we (QE) call a tier #1 installation test suite. They can be found in git. The tests are base on beakerlib and the legacy RHTS framework which is now part of Beaker.
This effort has been coordinated with Kamil as part of a pilot project he's responsible for. I've been executing the same test suite against earlier Fedora 20 snapshots but using an internal environment. Now everything is going out in the open.
Executing The Tests
Well you can't do that - YET! There are command line client tools for Fedora but Beaker and SNAKE are not well suited for use outside a restricted network like LAN or VPN. There are issues with authentication most notably for SNAKE.
At the moment I have to ssh through two different systems to get proper access. However this is been worked on. I've read about a rewrite which will allow Beaker to utilize a custom authentication framework like FAS for example. Hopefully that will be implemented soon enough.
I will also like to see the test systems have direct access to the Internet for various reasons but this is not without its risks either. This is still to be decided.
If you are interested anyway see the kick-tests.sh file in the test suite for
examples and command line options.
Test Results
The first successfully completed test jobs are jobs 50 to 58. There's a failure in one of the test cases, namely SELinux related RHBZ #1027148.
From what I can tell the lab is now working as expected and we can start doing some testing against Fedora development snapshots.
Ping me or join #fedora-qa on irc.freenode.net if you'd like to join Fedora QA!
There are comments.
Keeping Backwards Compatibility for pykickstart
Consider the following scenario:
- I'm using SNAKE templates as part of my installation testing work;
- SNAKE has a dependency on pykickstart;
- To test the latest and greatest kickstart features in Fedora we need the latest version of pykickstart;
- Latest pykickstart needs Python 2.7
- Python 2.7 is not available on RHEL 6 which is used to host the test infrastructure.
Just yesterday I hit an issue with the above setup and figured Fedora QA is in a kind of strange situation - we always need the latest but need it conservative enough to run on RHEL 6. See the original thread at kickstart-list.
In this particular case the solution will be to remove the offending code and implement the same functionality in backward-compatible manner. Also add more tests. I will be working on this tomorrow (there's an older patch already).
The BIG question remains though - how do you manage software evolution and still keep it compatible with older execution stacks? Please share your experience in the comments section.
PP: Spoiler - this is part of an ongoing effort to bring open source installation testing expertise (my domain) into Fedora world, plus establish a community supported test infrastructure. More info TBA soon.
There are comments.
Fedora 20 GNOME 3.10 Test Day Post-mortem

Here is my summary of the second Fedora Test Day hosted at init Lab yesterday.
Local attendance was a total disaster, in fact I was testing once again by my own. This time there were more people in the lab, all busy with their daily routines and tasks. There were no people who came for the testing :(. I will have to try different venues in the future and see if the situation improves.
On the testing front I managed to score 5 bugs against GNOME and Fedora. You can see the other test results and bugs on the wiki.
There are two things I didn't like in particular
- GNOME 3 as well as its classic mode - simply not the environment I'm used to;
- Having to record test results in the wiki! I'm writing to the Fedora QA mailing list about that as we speak.
At one time I was engaged in a discussion about which Bulgarian keyboard layout should be the default in GNOME simply because of GNOME #709799. The default keyboard layout will be Bulgarian (traditional phonetic) aka bg+phonetic.
(16,13,26) rtcm: atodorov: are you bulgarian and/or live in bulgaria?
(16,14,20) rtcm: atodorov: if yes, I wanted to know which keyboard layout most people expect there to be the default
(16,16,34) atodorov: rtcm: I'm a Bulgarian, however I can't tell which one. Both Phonetic and standard (BDS) are common
(16,16,54) atodorov: a safe bet is to go with phonetic I guess.
(16,19,46) rtcm: atodorov: can you tell me which one is it in XKB terms? is it "bg", "bg+bas_phonetic" or "bg+phonetic" ?
(16,20,51) rtcm: they're labeled as "Bulgarian", "Bulgarian (new phonetic)" and "Bulgarian (traditional phonetic)"
(16,21,30) atodorov: bg+phonetic is the traditional phonetic
(16,22,04) atodorov: bg labeled as "Bulgarian" is the standard one I guess. Here we call it BDS after the standardization institute
(16,22,34) atodorov: bg+bas_phonetic is created from the Bulgarian Academy of Science and is not very popular as far as I know. I've never seen it in use
(16,23,15) rtcm: atodorov: all I want to know is what most people would expect? like what does windows do by default? that's a good bet
(16,27,46) atodorov: rtcm: I'm just being told that new Windows releases use yet another layout by default, which is like phonetic but with some characters in new places and people don't like that
(16,27,53) atodorov: my safe bet goes to bg+phonetic
(16,29,05) rtcm: ok, thanks
It is a rare occasion when you get to make a decision that affects a large group of people and I hope you don't hate me for that!
Do you want to see more Fedora Test Days happening in Sofia? Join me and I will organize some more!
There are comments.
Fedora 20 Virtualization Test Day Post-mortem

Here is a quick summary of the first Fedora Test Day in Sofia I hosted at init Lab today.
Attendance was quite poor, actually nobody else except me participated but almost nobody else visited the hackespace as well. I get that it is a working day and Test Days conflict with regular business hours but this is not going to change anyway. On the other hand where were all the freelancers and non-office job workers who usually hang around in the Lab? I have no idea!
On IRC there was much better activity, 5 or 6 people were testing across Asia, Europe and USA time zones. You can see the test results here. I've started filing quite a few bugs in the morning and continued well into the afternoon. I've managed to file a total of 10 bugs. Some of them were not related to virtualization and some of them turned out to be duplicates or not a bug. I even managed to file 2 duplicate bugs which likely have the same root cause myself :).
I've also experienced two bugs filed by other people: RHBZ #967371 for MATE desktop and RHBZ #1015636 for virt-manager's Save/Restore functionality.
I've tried ARM on x86_64 but that didn't get anywhere near a running system. I will make another post about ARM and what I've discovered there.
The one thing I liked is the test results application. It is not what I'm used to when dealing with RHEL, has far less features but is very fast and easy to use and suits the Test Days participants just fine. And is definitely much easier to use compared to filing results in the wiki.
Overall Fedora 20 virtualization status according to me is pretty good.
I hope to see more attendance on Thursday when we're going to test GNOME 3.10.
There are comments.
Fedora 20 Virtualization & GNOME Test Days at init Lab this week
Fedora 20 Virtualization and GNOME test days will be tomorrow (8th Oct) and on Thursday (10th Oct)! Local community in Sofia will gather at init Lab! We start at 10:00 and everybody is welcome.
If you have no idea what I'm talking about check my previous posts and the announcement at init Lab's website:
- http://initlab.org/event/testing-fedora-20-virtualization-test-day
- http://initlab.org/event/gnome-test-day
See you there!
There are comments.
Facebook UI Bug Strikes Again at HackFMI
Does this look familiar to you ?

No? See SofiaValley and opensource.com.
Either this is a very common front-end mistake (I would blame CSS) or Facebook have screwed up their buttons.
There are comments.
Fedora Test Days are Coming to Sofia
As I mentioned earlier I will organize some Fedora testing in Sofia. Here's an outline of my talk this Saturday and a general guide for anyone who wants to participate.
What are Fedora Test Days
Fedora Test Days are day long events focused on testing a particular feature in the upcoming Fedora release. At the time of writing they are focused on Fedora 20.
What You Need Before Joining Fedora
- A bugzilla.redhat.com account;
- A Fedora account. Please complete the onboarding process in advance as it takes time;
- Create a wiki page for your profile. Mine is here. This will verify you can edit the wiki;
- Know how to use IRC. There is a web chat client at https://webchat.freenode.net/.
What You Need Before The Test Day
- Know how to properly report a bug;
- Installation ISO (DVD) or Live CD depending on what you want to test;
- Nightly LiveCD ISOs can be found here;
- Another alternative is official test compose (TC) images or yum update to the latest release;
- Extra hardware or a virtual machine for testing.
What You Need On The Test Day
- Join the #fedora-test-day IRC channel on freenode.net;
- Have the current test day wiki page handy;
- Execute some test cases and file bugs;
- Report your test results on the wiki;
Time and place for two test days will be announced at the end of the week and earlier next week so stay tuned!
There are comments.
Lenovo Rants: Battery and Dock Flaws
To all my readers - sorry for not being able to blog more frequently lately. Here's an easy read about my favourite laptop brand Lenovo and some of their design flaws I've found.
X220 and T60 Batterries are ALMOST Identical

As you can see the X220 and T60 batteries are nearly identical with the notable exception of the connector placement. The end result - I have to purchase yet another battery as a backup for long travel/work on the go. Not what I want.
I wish all Lenovo models had the same batteries so people can swap them around as they wish. Is this too much to ask for? Have you seen another brand which got this right?
ThinkPad Mini Dock Design Flaw
I'm using a ThinkPad Mini Dock Series 3 docking station with my X220 laptop. Being a QA engineer for so long I immediately noticed something that wasn't quite right. The buttons on the left and the mechanism next to them are blocking the hot air exhaust from the CPU fan. This model of docking station is made to fit several models of laptops and those which dock in position 2 are less affected from those which dock in possition 1. Mine was not a lucky one.

On the pictures below it is clearly visible that most of the hot air coming out of the CPU fan is blocked.



In order to reduce laptop heating and provide better cooling I decided to remove the 1/2 position switch mechanism. To do that you have to unscrew all screws from the docking station and carefully split the top and bottom halves. The offending piece of plastic is screwed with two tiny screws at the bottom. Once they are removed everything comes off.

Even with this piece removed my laptop still hets up too much! I guess 80 C is just normal for the Core i7 processors :(.
Have you found something not quite right in your hardware design? Please share in the comments.
There are comments.
Upcoming Talk: Fedora Test Days in Sofia
On September 28th I will be giving a short talk about Fedora Test Days at the regular Linux for Bulgarians conference. I will explain what these are and how one can participate. I will also announce my plans and schedule to organize some Fedora 20 test days locally in Sofia. If you are a fan of Fedora and want to file bugs and kick some developers' ass this is the way to do it!
Other talks include Alexander Shopov's „Oracle's take on NoSQL“ which I wanted to hear since this summer and TBA talks about MicroTik routers.
The conference will take place on September 28th at the French Institute at Sofia University (see map). It starts at 13:00 and my talk should be at the beginning. See you there!
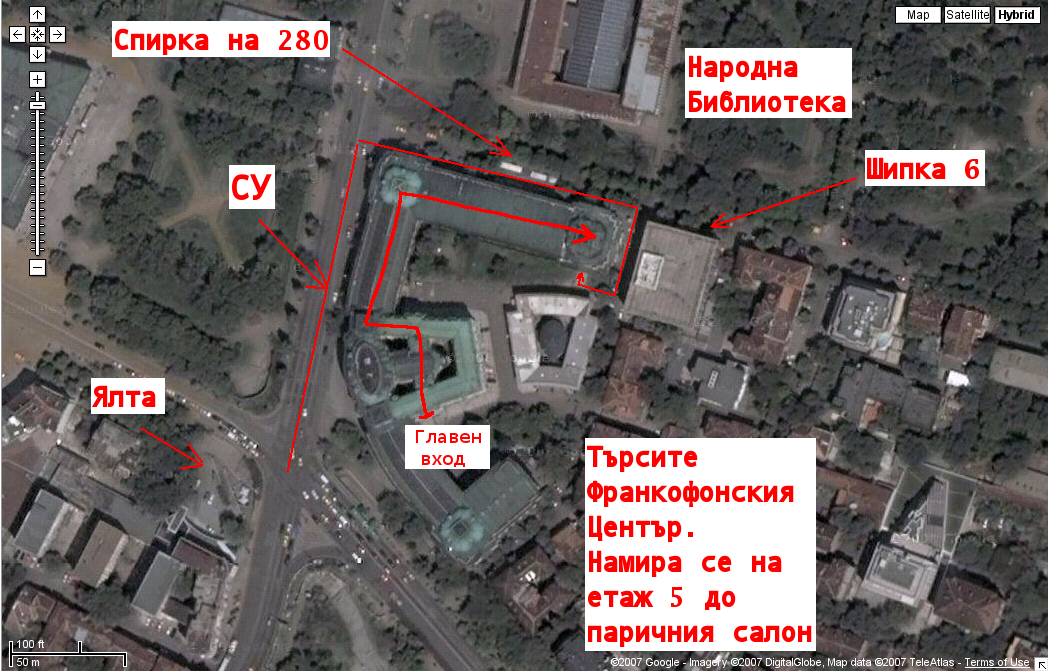{kind=link}
PS: this post was initially written on my BlackBerry Z10 with Penzus Editor - another small step in retiring my laptop.
There are comments.
Bug Analysis Of RHBZ #1337
In my previous post I asked the readers of this blog to pick a bug number from Red Hat's Bugzilla so I can analyze it later.
Radoslav Georgiev decided to step up and selected the Leet bug https://bugzilla.redhat.com/show_bug.cgi?id=1337
This is a rather old bug against kernel, in particular against the token ring driver. There isn't much info on the bug but it seems the issue is hardware dependent and doesn't reproduce reliably.
Looking at the bug status and history it looks like it was closed without fixing it. Most likely the reason for this was there was no hardware to test, bug was not reproduced and no customers were seeing the issue or were willing to test and work with devel!
If you'd like to see my comments on other interesting bugs just post a link to them in the comments section.
There are comments.
Red Hat's Bugzilla Hits One Million Bugs

Red Hat's Bugzilla passed the 1 million bugs milestone yesterday! RHBZ #1000000 has been filed by Anton Arapov, a kernel engineer and a very nice guy (I know him btw). I've filed several bugs yesterday but the last one was #999941. A bit too short!
To celebrate this event I dare you to pick some bugs from Bugzilla that you find interesting or frustrating and I will try to analyze and explain them from a QA engineer's point of view. Since I've reported over 1000 bugs and been involved in another close to 5000 I think I will be able to answer almost any question.
Challenge accepted!
There are comments.
Small But Annoying Twitter Bug

I've been having troubles with Twitter lately but this bug is just annoying! Where on Earth is the "code below" ? I've already reported it. Let's see how long it takes for them to fix it!
There are comments.
Notes From Two Interesting GUADEC Talks
As this year's GUADEC is coming to an end I'm publishing an interesting update from Petr Muller for those who were not able to attend. Petr is a Senior Quality Engineer at Red Hat. His notes were sent to an internal QE mailing list and re-published with permission.
As this year's GUADEC happened in the same building where I have my
other office, I decided to attend. I'm sharing my notes from the two
sessions I consider to be especially interesting for the audience of
this mailing list:
== How to not report your UX bug ==
Speaker: Fabiana Simões
Blog: http://fabianapsimoes.wordpress.com/
Twitter: https://twitter.com/fabianapsimoes
Do not do this stuff:
* Do not simply present a preferred solution, but describe a problem (a
difficulty you are having, etc.)
* Do not use "This sucks" idiom, not even hidden in false niceties like
"It's not user friendly"
* Do not talk for majority, when you are not entitled to ("most users
would like")
* Do not consider all UX issues as minor: an inability to do stuff is
not a minor issue
What is actually interesting for the designer in a report?
* What were you trying to do?
* Why did you want to do it?
* What did you do?
* What happened?
* What were your expectations?
More notes
* Write as much as needed
* Describe what you see, did and *how you felt*
* Print screen is your friend!
* *Give praise*
== Extreme containment measures: keeping bug reports under control ==
Speaker: Jean-Francois Fortin Tam
Homepage: http://jeff.ecchi.ca
Twitter: https://twitter.com/nekohayo
Discussed the problem lot of OS projects are having: lot of useless
(old, irrelevant, waiting for decision no one wants to make) bug/rfe
reports in their bug tracking systems. Lots of food for thought about
our own projects, internal or external. Clever applications of
principles from personal productivity systems such as GTD and Inbox Zero
for bug tracking.
The talk was mostly an applied version of this blog post, which is worth
reading:
http://jeff.ecchi.ca/blog/2012/10/08/reducing-our-core-apps-software-inventory/
I particularly like the UX bug reporting guide lines. Need to take those into account when reporting UI issues.
I still haven't read the second blog post which also looks interesting although not very applicable to me. After all I'm the person reporting bugs not the one who decides what and when gets fixed.
There are comments.
UI Bug for OpenSource.com

A simple bug with the Facebook like and share widget. Looks familiar? Indeed it is! SofiaValley had the same bug 2 months ago.
Already reported and hopefully they fix it.
There are comments.
Performance test: Amazon ElastiCache vs Amazon S3
Which Django cache backend is faster? Amazon ElastiCache or Amazon S3 ?
Previously I've mentioned about using Django's cache to keep state between HTTP requests. In my demo described there I was using django-s3-cache. It is time to move to production so I decided to measure the performance difference between the two cache options available at Amazon Web Services.
Update 2013-07-01: my initial test may have been false since I had not configured ElastiCache access properly. I saw no errors but discovered the issue today on another system which was failing to store the cache keys but didn't show any errors either. I've re-run the tests and updated times are shown below.
Test infrastructure
- One Amazon S3 bucket, located in US Standard (aka US East) region;
- One Amazon ElastiCache cluster with one Small Cache Node (cache.m1.small) with Moderate I/O capacity;
- One Amazon Elasticache cluster with one Large Cache Node (cache.m1.large) with High I/O Capacity;
- Update: I've tested both
python-memcachedandpylibmcclient libraries for Django; - Update: Test is executed from an EC2 node in the us-east-1a availability zone;
- Update: Cache clusters are in the us-east-1a availability zone.
Test Scenario
The test platform is Django. I've created a
skeleton project
with only CACHES settings
defined and necessary dependencies installed. A file called test.py holds the
test cases, which use the standard timeit module. The object which is stored in cache
is very small - it holds a phone/address identifiers and couple of user made selections.
The code looks like this:
import timeit
s3_set = timeit.Timer(
"""
for i in range(1000):
my_cache.set(i, MyObject)
"""
,
"""
from django.core import cache
my_cache = cache.get_cache('default')
MyObject = {
'from' : '359123456789',
'address' : '6afce9f7-acff-49c5-9fbe-14e238f73190',
'hour' : '12:30',
'weight' : 5,
'type' : 1,
}
"""
)
s3_get = timeit.Timer(
"""
for i in range(1000):
MyObject = my_cache.get(i)
"""
,
"""
from django.core import cache
my_cache = cache.get_cache('default')
"""
)
Tests were executed from the Django shell on my laptop
on an EC2 instance in the us-east-1a availability zone. ElastiCache nodes
were freshly created/rebooted before test execution. S3 bucket had no objects.
$ ./manage.py shell
Python 2.6.8 (unknown, Mar 14 2013, 09:31:22)
[GCC 4.6.2 20111027 (Red Hat 4.6.2-2)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
>>> from test import *
>>>
>>>
>>>
>>> s3_set.repeat(repeat=3, number=1)
[68.089607000350952, 70.806712865829468, 72.49261999130249]
>>>
>>>
>>> s3_get.repeat(repeat=3, number=1)
[43.778793096542358, 43.054368019104004, 36.19232702255249]
>>>
>>>
>>> pymc_set.repeat(repeat=3, number=1)
[0.40637087821960449, 0.3568730354309082, 0.35815882682800293]
>>>
>>>
>>> pymc_get.repeat(repeat=3, number=1)
[0.35759496688842773, 0.35180497169494629, 0.39198613166809082]
>>>
>>>
>>> libmc_set.repeat(repeat=3, number=1)
[0.3902890682220459, 0.30157709121704102, 0.30596804618835449]
>>>
>>>
>>> libmc_get.repeat(repeat=3, number=1)
[0.28874802589416504, 0.30520200729370117, 0.29050207138061523]
>>>
>>>
>>> libmc_large_set.repeat(repeat=3, number=1)
[1.0291709899902344, 0.31709098815917969, 0.32010698318481445]
>>>
>>>
>>> libmc_large_get.repeat(repeat=3, number=1)
[0.2957158088684082, 0.29067802429199219, 0.29692888259887695]
>>>
Results
As expected ElastiCache is much faster (10x) compared to S3. However the difference between the two ElastiCache node types is subtle. I will stay with the smallest possible node to minimize costs. Also as seen, pylibmc is a bit faster compared to the pure Python implementation.
Depending on your objects size or how many set/get operations you perform per second you may need to go with the larger nodes. Just test it!
It surprised me how slow django-s3-cache is.
The false test showed django-s3-cache to be 100x slower but new results are better.
10x decrease in performance sounds about right for a filesystem backed cache.
A quick look at the code of the two backends shows some differences. The one I immediately see is that for every cache key django-s3-cache creates an sha1 hash which is used as the storage file name. This was modeled after the filesystem backend but I think the design is wrong - the memcached backends don't do this.
Another one is that django-s3-cache time-stamps all objects and uses pickle to serialize them. I wonder if it can't just write them as binary blobs directly. There's definitely lots of room for improvement of django-s3-cache. I will let you know my findings once I get to it.
There are comments.
Even Facebook has Bugs
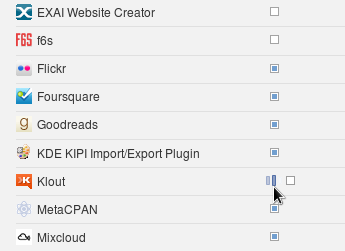
Here's a small but very visible UI bug in Facebook. While selecting for which applications to receive or not notifications there is a small progress bar image that appears left of the checkbox element. The trouble is this image displaces the checkbox and it appears to float right and left during the AJAX call. This is annoying.
There's an easy fix - either fix the progress image and checkbox positions so they don't move or place the image to the right.
In my practice these types of bugs are common. I usually classify them with High priority, because they tend to annoy the user and generate support calls or just look unprofessional.
There are comments.
SofiaValley UI bug
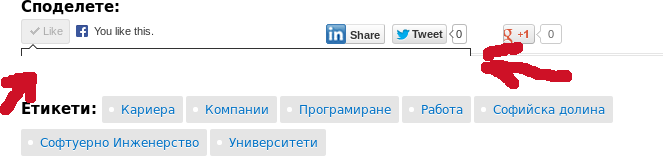
SofiaValley recently had a bug in their UI. As seen above when clicking the Like button the widget would overlap with other visual elements. At first this doesn't look like a big deal but it blocks the user from sharing the page via Facebook which is important for a blog.
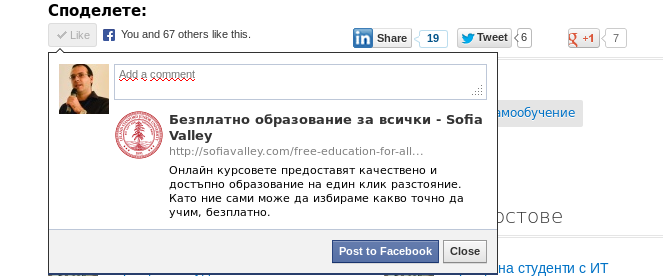
I have reported the error and it was fixed very quickly. +1 for SofiaValley.
Have you spotted any other interesting bugs? Let me know and they will be published here.
There are comments.
Linux and Python Tools To Compare Images
How to compare two images in Python? A tricky question with quite a few answers. Since my needs are simple, my solution is simpler!
 dif.io homepage before and after it got a G+1.
dif.io homepage before and after it got a G+1.
ImageMagic is magic
If you haven't heard of ImageMagic then you've been
living in a cave on a deserted island! The suite contains the compare command
which mathematically and visually annotates the difference between two images.
The third image above was produced with:
$ compare difio_10.png difio_11.png difio_diff.png
Differences are displayed in red (default) and the original image is seen in the
background. As shown, the Google +1 button and count has changed between the two
images. compare is a nice tool for manual inspection and debugging.
It works well in this case because the images are lossless PNGs and are regions of
screen shots where most objects are the same.
 Chestnuts I had in Rome. 100% to 99% quality reduction.
Chestnuts I had in Rome. 100% to 99% quality reduction.
As seen on the second image set only 1% of JPEG quality change leads to many small differences in the image, which are invisible to the naked eye.
Python Imaging Library aka PIL
PIL is another powerful tool for image manipulation. I googled around and found some answers to my original questions here. The proposed solution is to calculate RMS of the two images and compare that with some threshold to establish the level of certainty that two images are identical.
Simple solution
I've been working on a script lately which needs to know what is displayed on the screen and recognize some of the objects. Calculating image similarity is quite complex but comparing if two images are exactly identical is not. Given my environment and the fact that I'm comparing screen shots where only few areas changed (see first image above for example) led to the following solution:
- Take a screen shot;
- Crop a particular area of the image which needs to be examined;
- Compare to a baseline image of the same area created manually;
- Don't use RMS, use the image histogram only to speed up calculation.
I've prepared the baseline images with GIMP and tested couple of scenarios
using compare. Here's how it looks in code:
from PIL import Image
from dogtail.utils import screenshot
baseline_histogram = Image.open('/home/atodorov/baseline.png').histogram()
img = Image.open(screenshot())
region = img.crop((860, 300, 950, 320))
print region.histogram() == baseline_histogram
Results
The presented solution was easy to program, works fast and reliably for my use case. In fact after several iterations I've added a second baseline image to account for some unidentified noise which appears randomly in the first region. As far as I can tell the two checks combined are 100% accurate.
Field of application
I'm working on QA automation where this comes handy. However you may try some lame CAPTCHA recognition by comparing regions to a pre-defined baseline. Let me know if you come up with a cool idea or actually used this in code.
I'd love to hear about interesting projects which didn't get too complicated because of image recognition.
There are comments.
Bug in the Fridge

Once you've been into
Quality Assurance
for 5+ years you start to notice bugs everywhere
and develop a sixth sense for it. Today I found a bug in my
Liebherr
KBGB 3864 refrigerator, caused by what looks like a race-condition.
This appliance starts beeping in case the door is left open for more than 60 seconds. The alarm stops if door is closed or can be muted manually while the door is still open.
The Bug
It happened so that I had the door open for nearly one minute and as it was closing I heard a beep. This time however the beeping didn't stop after the door had closed. The alarm continued beeping with the door closed so I tried to re-open and close it again. It didn't stop! I had to open the door and manually mute the alarm for it to stop.
The Root Cause
While not entirely sure, I think the reason for this malfunction was a race-condition. The alarm went on at nearly the same time when the controlling timer should have gone off (when closing the door).
Steps To Reproduce
I tried reproducing several times afterwards by opening and closing the door at the last possible moment. I used a stop-watch to time my actions. However I wasn't able to reproduce twice. Every time I tried, there was only one single beep as the door was closing and no more.
I guess then, like we say in QE, WORKS FOR ME!
There are comments.
Page 6 / 7